与其他连接池不同,druid没有一个专门的连接池类,比如ConnnetPool。druid的连接池都交给了DruidDataSource负责管理,用数据connects存放连接。本文将介绍 Druid 是如何维护这个连接池,如何完成连接的获取和回收。
连接是一种昂贵资源,每次创建销毁需要开销。Druid 可以看做一家 数据库连接池的租赁公司,负责租赁连接,出租给需要的用户,用户使用完成就返还给 Druid。用户就不用关心连接池的创建和销毁细节。因为资源有限 Druid 只能维持有限的连接数量。
一.数据结构
首先看druid 是通过怎样的数据结构存储连接:
1
2
3
4
5
6
7
8
9//连接池
private DruidConnectionHolder[] connections = new DruidConnectionHolder[maxActive];
private int poolingCount = 0; // 当前连接池中数据库连接的数量
private int activeCount = 0; // 正在使用的连接数量
// 线程之间的通讯
protected Condition notEmpty;
protected Condition empty;
protected ReentrantLock lock; // 保证现在安全
connections 存放着当前可用的所有连接,但这些连接不是 druid 的所有连接,druid 还有一部分连接可能正在被使用,这部分可能就租给用户使用了。connections 存放的是一个代理类,将连接做一层包装。在代理类中可以做很多事情,比如监控拦截、统计等。同时在执行 close 时不直接关闭,可以在这里做资源回收操作。
- poolingCount 是当前可用连接数量,即存放在 connections 中的链接数量。
- activeCount 是当前正在被使用的连接数量,这部分已经被用户拿去使用还没归还。
poolingCount + activeCount 的数量才是 druid 拥有的所有连接数量。
这里为什么可用使用数组结构存储呢? 数据库连接池在初始化时就已经指定了可分配连接的最大数量 maxActive,因此存储空间是固定的。
Druid 还有三个重要的属性:
- notEmpty: 不为空通知。用来通知其他线程池已经有可用连接。如果没有连接了 notEmpty 上等待,将线程挂起,等待数据库连接;当有新的连接的时候就 通过 notEmpty 进行通知广播等待的线程
- empty: 空通知。 用来通知其他线程目前没有可用连接,通知创建新连接。创建线程在 empty 上等待,发现有empty 信号时就会去创建连接。
- lock: 是一把全局锁,为了保证在多线程环境下对 connections、poolingCount、activeCount 操作的数据一致性。因此在涉及到这些参数变化的地方都使用这边锁。
二. 核心逻辑
DruidDataSource 是数据库连接池的核心部分,可以看做是 Druid 连接池租赁公司的老板。 这家公司创立之初,老板会去中招聘其他三位核心成员:
- 创建连接池线程 CreateConnectionThread。主要职责就是创建连接,当连接不够的时候都是交给他创建,满足用户对连接的需求。
- 销毁连接线程 DestroyConnectionThread。 主要职责线程池的销毁,将一些空闲连接、不健康连接清除,维持一个最小空闲连接数。
- 日志线程 LogStatsThread。 可以看做公司的财务,每隔一段时间记录连接的消费和使用细节。
DruidDataSource 在初始化的时候就 创建以上三个线程。初始化时还会做以下几个事情:
- 将 connections 初始化,大小设置为 maxActive。 一旦创建好以后就不能发生变化了,连接最大数量不能改变。
- 根据用户配置的 minActive 数量初始化连接,这样启动以后就有直接可用的连接。为了提高启动速度也可以将这个初始化工作进行异步化(druid.asyncInit 参数设置为true即可)。
在介绍公司是如何运作之前,需要简单介绍在 druid 中几个永恒的准则。
- 连接池数量最大不能超过 maxActive.
- 最小连接数不能低于 minIdle.
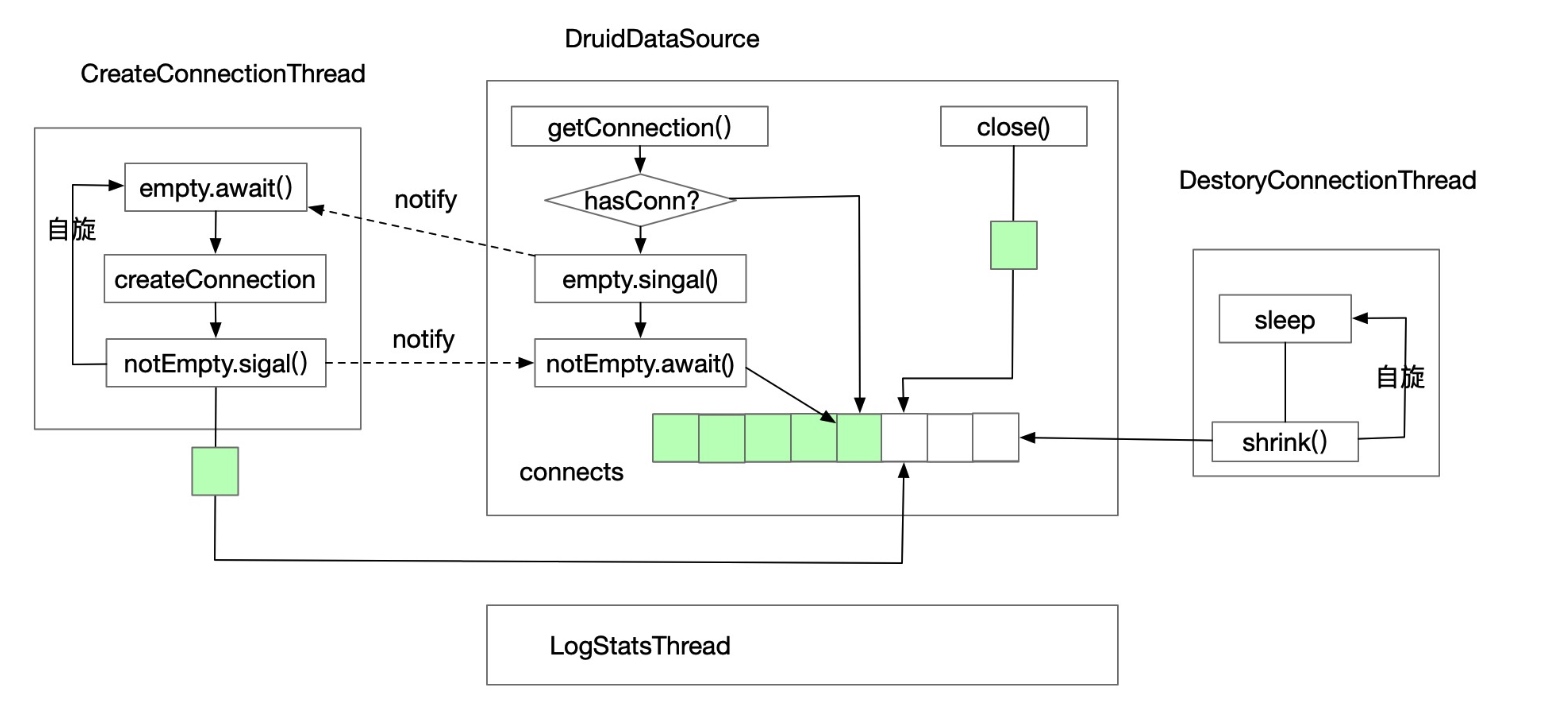
- 用户通过DruidDataSource 去获取和回收连接。
- 获取连接时首先判断连接池是否有可用连接,如果有直接从conecets 尾部获取一个。否则发送empty 信号告诉 CreateConenctionThread 创建连接,并挂起等待,直到有新的连接。
- CreateConenctionThread 创建连接完成后,发起 notEmpty 通知等待线程。 等待线程恢复,并从connects 尾部获取连接。
- DestroyConnectionThread 负责收缩连接池,如果连接数量小于 minIdle 则通知 CreateConnectionThread.
- LogStatsThread 则负责记录日志。
DruidDataSource
获取连接
当用户需要连接时,调用 dataSource#getConnection 方法。 DruidDataSource 首先需要判断当前线程池是否有可用的连接,如果有可用的连接则采用LRU策略获取,直接从 connections 尾部获取一个连接返回。 尾部的连接是当前连接池中最活跃的连接,要么是刚刚释放回去的连接,要么就是新创建的。 因此最大程度保证连接是可用的,健康的。
1 | decrementPoolingCount(); |
如果当前连接池没有可用的连接,那么首先会发一个信号告诉 CreateConnectionThread 去创建新的连接,然后将自己挂起直到有新的可用连接。新的连接会从两个地方获得,一个是 CreateConnectionThread,一个是刚刚回收的连接。
1
2
3emptySignal(); // send signal to CreateThread create connection
notEmpty.await(); // signal by recycle or creator
获取连接的时候提供了两种等待方式:
- getConnection() 进行无限等待, 直到有连接以后才返回。 这种会导致业务方无限等待。
- getConnection(nanos) 指定时间等待,如果在指定时间没有可用连接则直接返回。
连接从连接池中获取,有的连接在连接池中存放很久可能已经失去活性不能使用。因此在 druid 中支持连接获取后对连接校验的能力。 只要配置 testOnBorrow=true 并且配置 validationQuery即可, druid 连接活性校验方式实际上是通过执行sql 方式来验证,直接执行配置的 validationQuery 。
1
rset = stmt.executeQuery(validationQuery);
如果没有配置 testOnBorrow, druid 也支持在获取连接以后对于空闲很久的连接做检查,可以通过testWhileIdle开关设置。如果连接的空闲时间大于 timeBetweenEvictionRunsMillis, 则执行 validationQuery 检查连接的可用性。对于不可用的连接进行销毁,并再次获取新的连接。可以通过这些方式尽可能让连接处于活跃、健康状态。
回收连接
用户使用的Connection 是代理代理类 DruidConnectionHolder, 在执行 close 时不是直接将连接关闭,而是将连接回收。
回收时同时也支持对连接做个检查,将健康的连接存入到连接池。默认不检查,可以通过配置 testOnReturn=true, 则会执行 validationQuery 来检查连接是否可用。如果不可用则不回收,并销毁。回收的连接放在connects 末尾,存放完毕后发发一个 notEmpty 通知,通知正在等待连接的线程。
CreateConnectionThread
如名字所示,这个主要是一个负责创建连接。 不是时刻都在创建连接,当没有可用连接时,用户线程进入等待挂起状态,并且连接数量小于maxActive 时才创建连接,否则就偷懒睡觉。在他的世界里准守以下两个规则:
必须是存在线程等待(有用户获取连接时,此刻没有连接在排队等待,后文会介绍),才会去创建连接。 否则挂起线程睡眠等待。
1
2
3
4
5
6
7 // 必须存在线程等待,才创建连接
if (poolingCount >= notEmptyWaitThreadCount //
&& (!(keepAlive && activeCount + poolingCount < minIdle))
&& !isFailContinuous()
) {
empty.await();
}
如果当前连接数量小于 maxActive 才去创建,否则挂起睡眠等待。
1
2
3
4
5// 防止创建超过maxActive数量的连接
if (activeCount + poolingCount >= maxActive) {
empty.await();
continue;
}
如果以上两个规则满足了,则会去创建连接。创建连接的底层使用 JDBC 这一套逻辑, 利用Driver 和配置信息连接到数据库:
1
2conn = getDriver().connect(url, info);
创建完的连接直接存在 connections 末尾,并发一个notEmpty信号告诉所有在等待的线程。等待线程则从睡眠中恢复,再尝试去获取连接。
DestroyConnectionThread
该线程主要工作是将空闲及无效的连接销毁。 默认情况下每1000ms 执行一次,可以通过timeBetweenEvictionRunsMillis 时间设置执行间隔。 这里使用的是 最近最久未使用策略进行回收。创建连接和获取连接的时候都是从 connects 尾部获取,尾部连接相对活跃,而头部的连接可能长时间未被使用,相对而言活性更低。因此每次回收都是从connects 头部开始遍历,主要回收几类连接:
连接的空闲时间大于 maxEvictableIdleTimeMillis, 则进行回收。
大于minIdle 部分的连接会被回收。 保证连接池空闲连接不会太多。如果连接池中有大于 minIdle 的连接,说明当前连接池不是很繁忙,因此可以清理。如果为了避免频繁销毁和关闭连接,建议设置 minIdle。
检查连接活跃度,不健康的连接则关闭。默认不检查,可以通过 druid.keepAlive 打开连接的健康检查,当开关打开以后,如果空闲时间超过 keepAliveBetweenTimeMills 则会判断连接的健康情况(默认 keepAliveBetweenTimeMills 是 2 分钟)。 这种在网络不稳定的场景下可以使用,利用 DestroyConnectionThread 的定时机制去检查连接状态,保证连接池连接的健康。
经过以上的情况,连接数量可能会小于 minIdle,则不能维持线程平衡。 那么就需要发送信号 emptySignal 通知创建连接线程去创建新的连接。
LogStatsThread
和公司中的会计一样负责记账,主要负责实施记录 Druid的开销情况,包括当前连接池数量、activeCount、这期间关闭的连接数量等等。 LogStatsThread 按配置的timeBetweenLogStatsMillis 的周期时间,定期执行。 如果 timeBetweenLogStatsMillis 没有配置,则该线程将不会被开启。