一. 概述
Kafka集群的一些重要信息都记录在ZK中,比如集群的所有代理节点、主题的所有分区、分区的副本信息(副本集、主副本、同步的副本集)。每个broker都有一个控制器,为了管理整个集群Kafka选利用zk选举模式,为整个集群选举一个“中央控制器”或”主控制器“,控制器其实就是一个broker节点,除了一般broker功能外,还具有分区首领选举功能。中央控制器管理所有节点的信息,并通过向ZK注册各种监听事件来管理整个集群节点、分区的leader的选举、再平衡等问题。外部事件会更新ZK的数据,ZK中的数据一旦发生变化,控制器都要做不同的响应处理。
控制器是实现kafka副本机制的核心组件。控制器工作包括:
- 主副本选举(PartitionLeaderSelector)
- 管理分区状态机(PartitionStateMachine)
- 管理副本状态机(ReplicaStateMachine)
- 管理多种类型的监听器
控制器通过注册多种监听器来完成相应的处理,启动的时候完成了以下监听器的注册:
- 在控制器中注册管理性质的监听器(重新分配分区、ISR改变、最优副本选举)
- 在分区状态机中注册更改主题的监听器
- 在副本状态机中注册更改代理节点的监听器
二. 主要流程
2.1 数据结构
两个关键的变量:
- partitionReplicaAssignment: 分配给分区的所有副本。比如
- partitionLeadershipInfo: 分区的主副本、ISR集合。用于主副本选举等。
控制器上下文对象可以认为是控制器工作时的数据存储和共享介质。控制器通过管理这些元数据,来管理集群的各个节点。当ZK节点发生变化时,控制器的监听事件会被触发,控制器根据ZK变化的值来更新本地的元数据。并根据分区和副本状态机的情况做响应的处理,最后会将结果同步给分区对应的所有broker。
2.2 选举主控制器
2.3.1 控制器
每个节点都要和ZK交互,它们作为ZK的客户端,会建立与ZK服务端的网络连接。每个节点都会启动一个控制器,但在所有的代理节点中还会选举一个主控制器。 代理节点在启动控制器会先注册一个回话实现的监听器(SessionExpirasionListener), 然后才通过选举器(ZookeeperLeaderElector)启动选举过程, 并在/controller节点注册数据改变监听器. 当会话失效或数据改变都会触发对应的监听器,让控制器重新参与选举。如图:
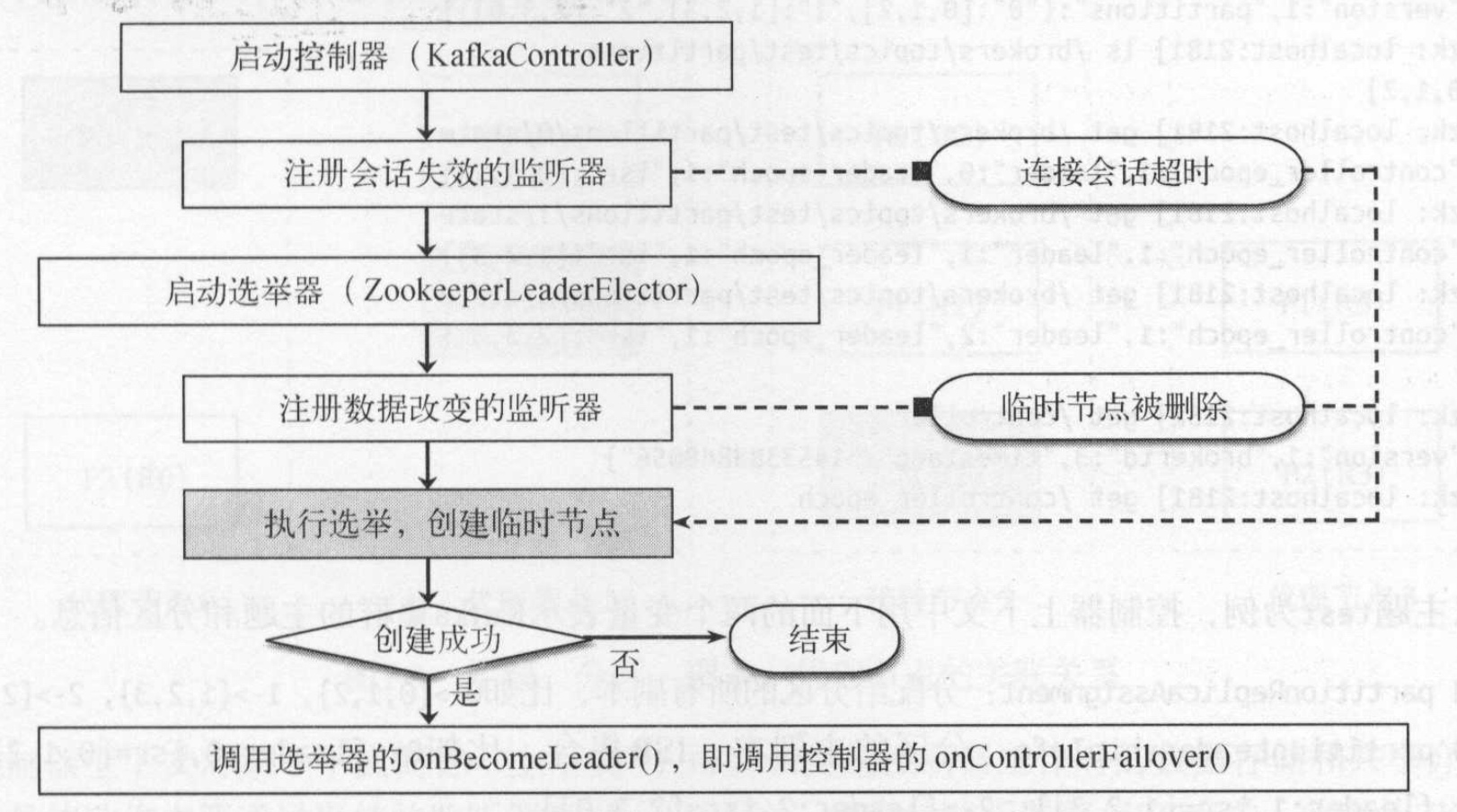
主控制器的选举主要利用的是ZK的leader选举机制,每个代理节点都会参与竞选主控制器,只有一个节点可以成为代理节点的主控制器。其他代理节点只有在主控制器出现故障或会话失效时参与领导选举。每个代理节点都会作为ZK客户端,向ZK服务端尝试创建/controller的临时节点, 最终只有一个代理节点可以成功创建/controller节点。
各节点启动的时候都会通过创建/controller 节点竞选主控制器,但只有一个成为主控制器。三个节点都会注册会话失效监听器,并在/controller节点注册数据改变监听器。
如果是主控制器产生会话失效,就会删除/controller临时节点。其他节点就会收到/controller节点的数据改变事件,它们的选举器都会尝试重新创建/controller竞选主控制器。
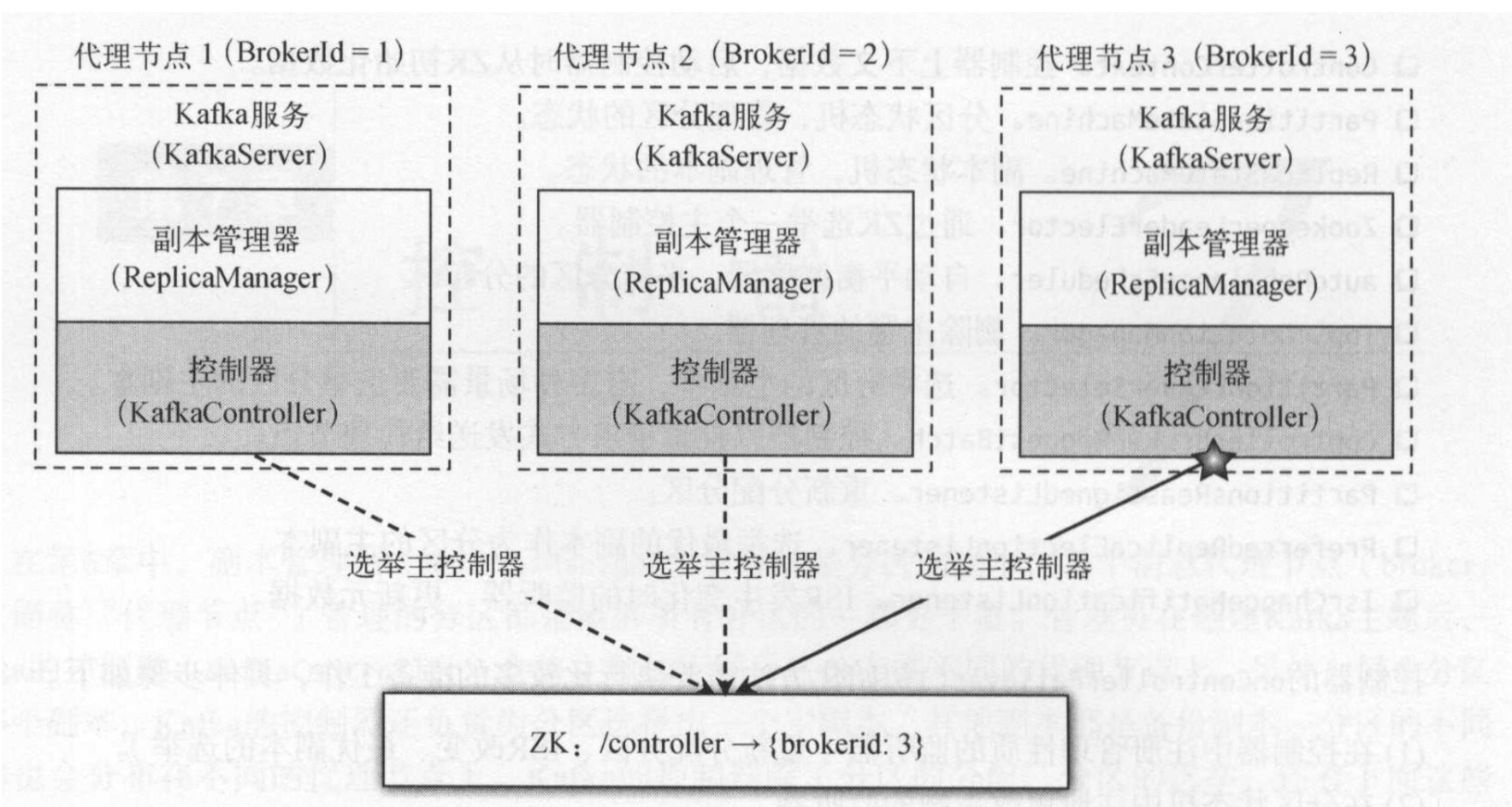
主控制器向ZK注册的监听器其实是Watcher, ZK的Watcher是一次性的。 因此使用完后需要重新再次注册。控制器的大部分逻辑都是通过注册的监听器来完成的:
- 首先控制器会向ZK节点注册监听器,每种监听器都有具体的事件处理器。
- ZK节点数据更新后,会触发监听器调用不同的回调方法
- 控制器执行具体的事件处理器,处理完成后,再次注册“监听器”,为下次事件触发做准备。
注册的监听器列表:
其中有三个事件是比较关键,通过这几个事件监听器来维护集群主副本的选举、故障转移和分区的分配管理等:
- TopicChangeListener. 会监听/brokers/kafkas/节点下变化事件,主要是监听主题的增加和删除事件。
- PartitionModificationsListener。 监听/brokers/topics/topic 节点的数据变化,比如增加分区等操作事件。
- BrokerChangeListener。 监听/brokers/ids, 监听代理节点的变化,如上线和下线事件。用于做再平衡和负载均衡处理。
控制器选举好后,控制器进行初始化,通道管理器会建立到集群各个代理节点的网络连接;初始化”选举最优副本作为主副本“、”重新分配分区“、”删除主题的管理器“等。控制器上掌握各及节点信息,同时掌握各个主题、分区、副本及ISR的信息。
2.3.2 zookeeper选举过程
zookeeper 3.4.0 以后采用了TCP版本的选举算法FastLeaderElection.
- 每个节点都发送投票,刚开始都会选择自己作为leader并广播其他节点。 投票格式(SID, ZXID), SID和ZXID是投票的服务器的值唯一ID和事务ID。
- 各个节点收到来自其他节点的投票
- 判断轮次,并更新轮次。
- 如果外部投票的轮次大于内部投票轮次,则立即更新自己的选举轮次。并清空所有已收到的投票,然后使用初始化的投票进行PK确认。
- 如果外部轮次小于内部轮次,则不做处理。
- 返回步骤2.
- 如果一致,则进行PK。
- 如果外部投票的轮次大于内部投票轮次,则立即更新自己的选举轮次。并清空所有已收到的投票,然后使用初始化的投票进行PK确认。
- 处理投票。 在收到投票后,针对每个投票,服务器都需要将别人的投票和自己的投票做PK。 PK规则:
- 优先检查ZXID。ZXID比较大的服务器优先作为leader.
- 如果ZXID相同的话,那么比较myid。 myid比较大的服务器作为leader服务器。
根据比较后,更新自己的投票,并在向其他所有机器发出投票信息。
- 统计投票。 服务器统计所有投票,如果已经超过半数的机器就作为Leader
- 改变服务器状态。 如果是Leader,就更新为LEADING. 如果是Follower就更新为FOLLOWER.
2.3 管理分区和副本状态机
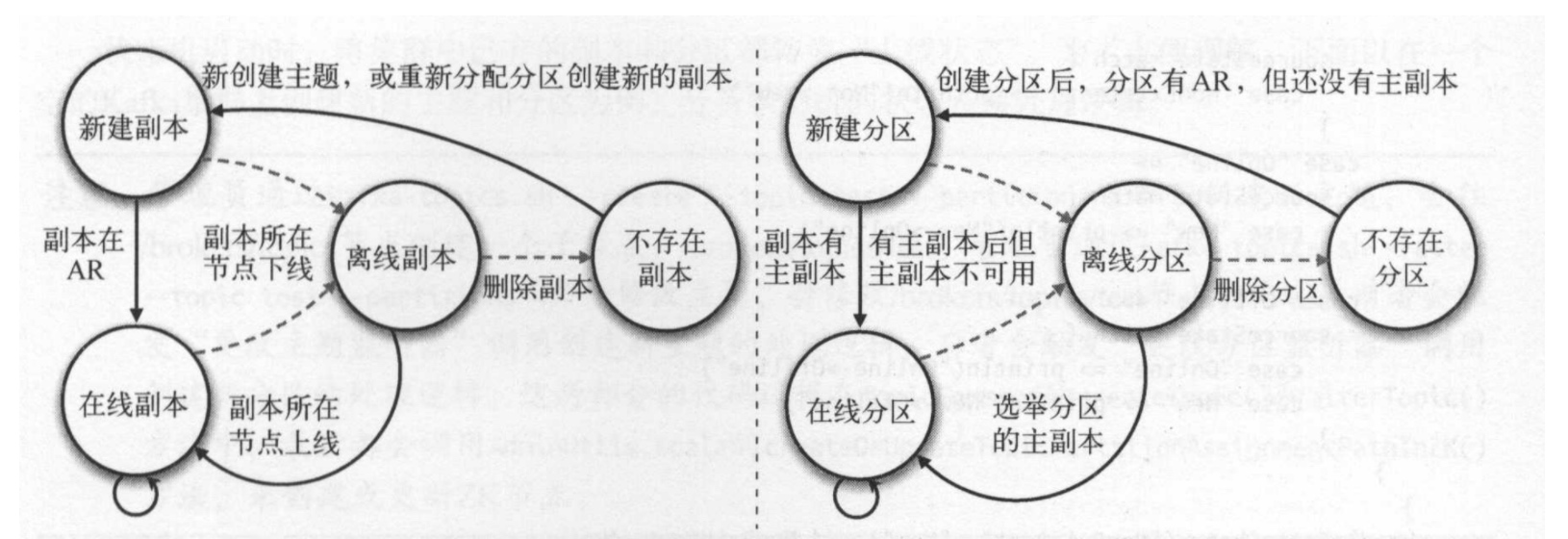
分区和副本都有四种状态: 新建、在线、离线和不存在。分区的四种状态为:
- 新增分区(NewPartition)
- 在线分区(OnlinePartition)
- 离线分区(OfflinePartition)
- 不存在分区(NonExistenPartition)
副本的四种状态:
- 新建副本(NewReplica)
- 在线副本(OnlineReplica)
- 离线副本(OfflineReplica)
- 不存在副本(NonExistentReplica)
当外部事件发生变化的时候会调用状态机的状态转移方法,根据不同的状态做出不同的响应。控制器通过分区和副本状态机来管理集群节点、实现主副本选举已经再平衡操作等。
- 分区从“新建分区”到“上线分区”采用固定算法选择主副本,即选举第一个副本作为分区的主副本。
- 从“下线状态”或“上线状态”转为“上线状态”,需要完成一次选举。
状态转移过程
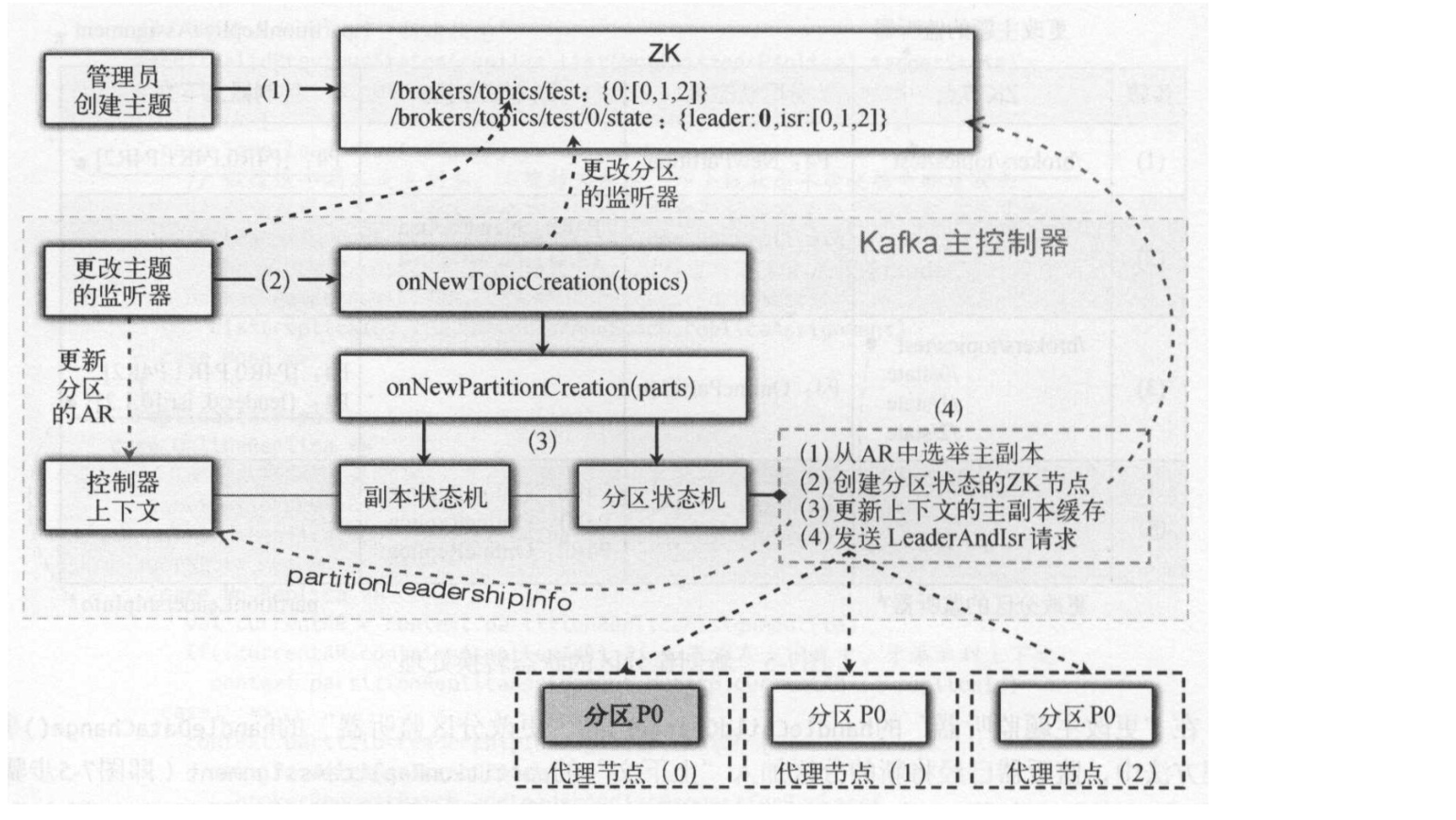
- 新建主题
1
kafka-topic.sh --create --topic test --partitions 3
创建主题test为例,新建主题时,会修改ZK节点/brokers/topics,创建了一个/brokers/topics/test的节点。而/brokers/topics该节点上的更改主题监听器(TopicChangeHandler)捕获创建主题事件。
- TopicChangeHandler首先会注册一个分区变更事件处理器PartitionModificationHandler。
- 调用newPartitionCreation(topics)方法,创建分区
- 更新分区状态从到“不存在状态”更新到“新建分区”状态 。 在转换前不存在分区,转换后分区有副本分区(因此可以执行后面的副本分区的处理)。
- 更新副本状态从“不存在状态”到“新建状态”。
- 更新分区状态从“新建状态”到“在线状态”。
- 调用zk创建各个副本节点
- 根据不同的当前状态,选择不同的分区选举类,为分区选举副本。
- 为新的分区初始化主副本和ISR
- 并将结果同步到分区对应的所有代理节点brokers
- 更新副本状态从“新建状态”到“在线状态” 。
- 创建分区
ZK创建分区和副本后,就会调用PartitionModificationHandler。 执行各种状态的变化。
初始化状态机
如果控制器在故障转移时,会分别启动副本状态机和分区状态机,并根据上下文初始化分区和副本的状态。
- 存活的副本,初始化为上线
- 不存活的副本,初始化为“删除失败”
- 分区有主副本,初始化为上线
- 分区有主副本,但不存活,则初始化为下线
- 分区没有副本,初始化为新建
2.4 选举主副本
分区从”下线状态“或”上线状态“到“上线状态”都要重新选举分区的主副本:
- 首先读取分区当前的主副本、ISR集合
- 优先从ISR中选择第一个副本作为主副本。 如果第一副本挂了,就会选择其他副本作为主副本。
- 如果ISR都挂了,那么就从AR(所有的副本)中选择第一个存活的副本作为主副本。
选择最优副本选举(第一个副本作为leader)是为了分区平衡,因为kafka的分区分配操作保证了分区的主副本会均匀的分布在所有节点上。kafka为了均衡将所有主副本均衡地分配到各个代理节点上。会有一个分区平衡的后台线程,定时检查最优副本(第一个副本)是不是主副本,如果不是则会进行重新选举,将最优副本作为主副本。
控制器会发送LeaderAndIsr请求给分区的所有存活副本,让这些代理节点更新元数据。
分区分配和重新分配
副本分配算法例如以下:
- 将全部N Broker和待分配的i个Partition排序.
- 将第i个Partition分配到第(i mod n)个Broker上.
- 将第i个Partition的第j个副本分配到第((i + j) mod n)个Broker上.
每一个topic的分区0都会被分配在broker 0上。第1个分区都分配到broker 1上。直到partition的id超过broker的数据才開始从头開始反复,这样会导致前面几台机器的压力比后面的机器压力更大。
因此。kafka是先随机挑选一个broker放置分区0,然后再按顺序放置其他分区。
以下图为例, 这里分区0放到了broker5中。分区1–broker6。分区2—broker7….: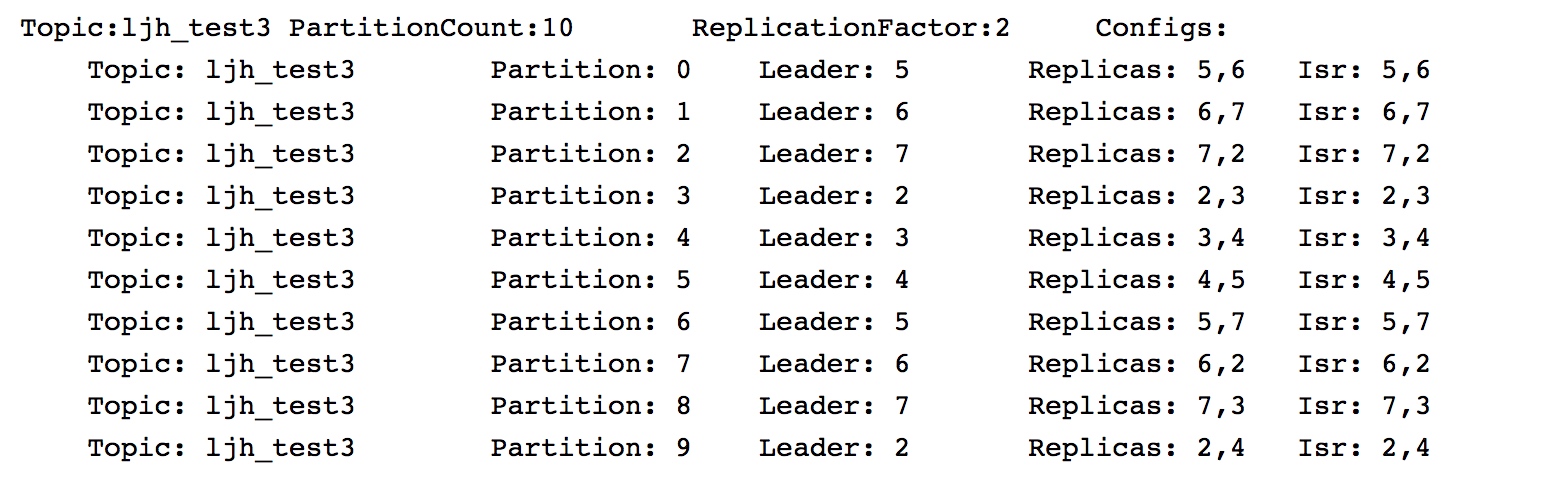
节点的上下线都会引起控制器进行分区重新分配,并选举主副本。控制器会发送LeaderAndIsr请求给分区的所有存活副本,让这些代理节点更新元数据。
2.5 管理多种类型的监听器
2.5.1 代理节点上下线
每个broker都有一个唯一的标识符,这个表示符可以指定指定也可以自动生成。在broker启动的时候,它会通过创建临时节点把自己的ID注册到ZK上,控制器监听/brokers/ids路径。当有broker上下线时,控制器就会得到通知。
代理节点上线过程:
- 控制器向其他节点发送请求更新元数据请求
- 将所有副本转为上线
- 如果主副本不是最优副本则重新选举主副本,并转换为在线
代理节点下线步骤:
- 将该代理节点上的所有分区的状态从“上线状态”设置为“下线状态”
- 如果节点上存在主副本分区,那么需要为这些分区重新选举主副本。
- 为分区选举主副本后,会发送LeaderAndIsr请求给分区所有存活的副本。即控制器通知分区所有的其他副本节点。
- 如果分区选举主副本后,将分区状态从“下线状态”改为上线状态
- kafka分区及副本在broker的分配