一. 概述
协调者GroupCoodinator 和控制器KafkaController一样,在每一个broker都会启动一个GroupCoodinator,Kafka 按照消费者组的名称将其分配给对应的GroupCoodinator进行管理;每一个GroupCoodinator只负责管理一部分消费者组,而非集群中全部的消费者组。而每个消费组都有唯一的一个协调者。
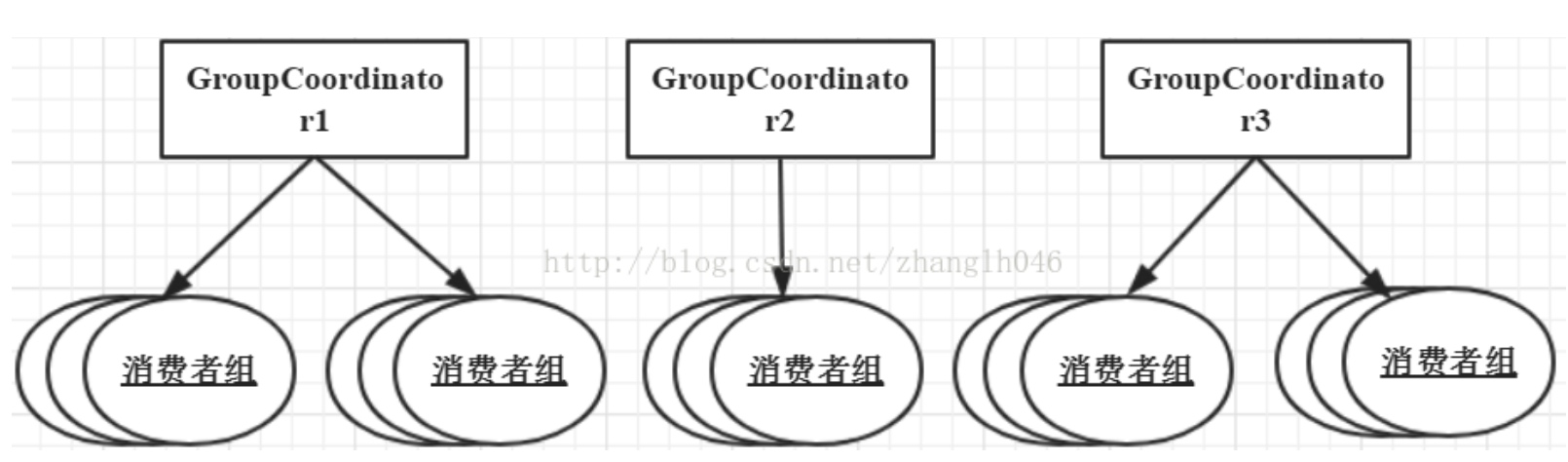
协调者主要是负责管理和协调消费者组的所有消费者,协调者是本身是一个broker节点服务,只是其主要用于为消费者组服务。如管理消费者之间的分区平衡操作、管理消费者的消费进度(消费偏移量)、监控消费者是否宕机、是否需要启动再平衡操作等。
协调者主要有两大功能:
- 作为消费组的偏移量存储介质(目前的偏移量不是存放在ZK上,而是存放在协调者上),记录消费者的对各个分区的消费进度。
- 作为消费者的分区平衡管理器。消费者通过定时给协调者发送心跳检测请求,以表示消费者的存活状态。协调者根据消费组中存活的消费者数量,按照分区分配算法给消费者均衡分配分区。
每个消费组都有唯一的一个协调者,协调者会保存消费组相关的元数据、消费者提交分区的偏移量给协调者,协调者更新消费组元数据。除了更新到日志文件,还会保存到缓存中,提高查询效率。
二. 偏移量的存储介质功能
众所周知,由于Zookeeper并不适合大批量的频繁写入操作,从0.8.2版本开始Kafka开始支持将consumer的位移信息保存在Kafka内部的topic中(从0.9.0版本开始默认将offset存储到Kafka内部的topic中),即__consumer_offsets topic,并且默认提供了kafka_consumer_groups.sh脚本供用户查看consumer信息。
协调者中保存了消费组元数据,包括了消费者提交的偏移量和消费组分配的状态数组,这两个数组都是以内部主题(_consumer_offsets)的形式存储在服务端的协调者节点上。 消费组元数据是按topic的形式存储,默认情况下__consumer_offsets有50个分区。消费元数据除了保存在日志文件中,还保存在协调者节点的内存缓存中。当节点宕机时,服务器除了需要处理主副本数据的故障转移,还会在其他节点上恢复缓存的数据。
__consumer_offsets的数据格式:
1 | [consumer group,topic name,partition] |
那么多代理节点,协调者是如何指定的呢?每个消费组元素数据是如何获取和存储的?如何指定存在哪个分区的?这时候就用到了group.id, Kafka会使用下面公式计算该group位移保存在__consumer_offsets的哪个分区上:
1 | Math.abs(groupID.hashCode()) % numPartitions |
计算得到的分区的主副本所在的代理节点就是该消费组所在的协调者。图中有三个消费组,他们的[group1, group2, group3], 通过以上计算公式得出该三个消费组的元数据分别在__consumer_offsets的P1、P2、P3三个分区上。并且这三个分区的主副本在代理节点1、2、3。 因此代理节点1、2、3分别是group1、 group2、group3的协调者节点。 消费元数据除了保存在日志文件中,还保存在协调者节点的内存缓存中,以提高检索速度。
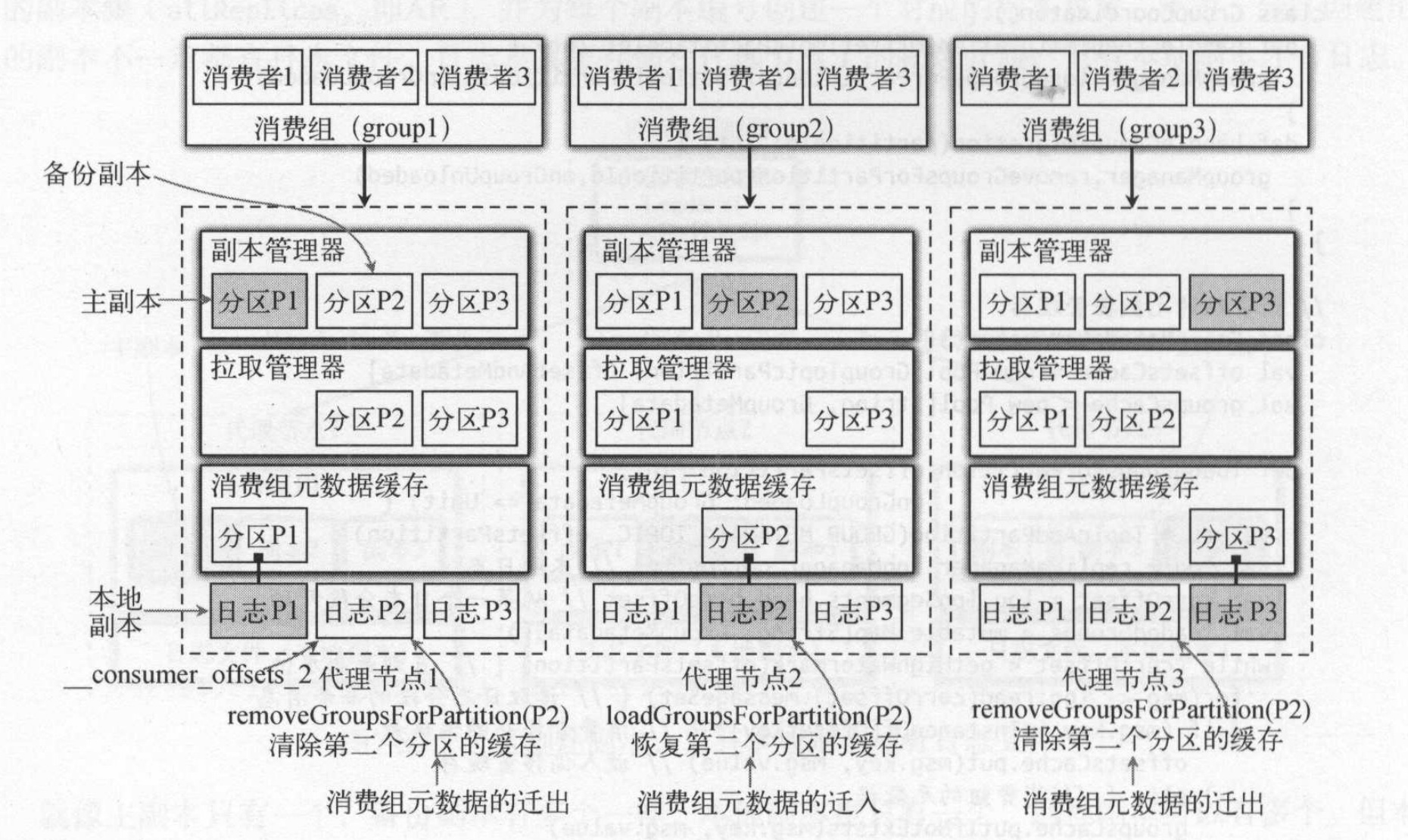
因为协调者是根据消费组在__consumer_offsets主题存储的分区主副本节点决定,因此协调者的选举和主副本一致,只要该分区的主副本选举出来,那么该消费组所在的协调者就确定了。
和其他topic一样,_consumre_offsets也是通过多副本的方式提高容错性和故障转移,一旦协调者节点挂了,则会转移到其他节点上。 消费组元数据在_consumre_offsets所在分区_consumre_offsets_1的主副本在代理节点1,代理节点1是协调者,该分区的其他副本分别存放在节点2,3上,如图所示: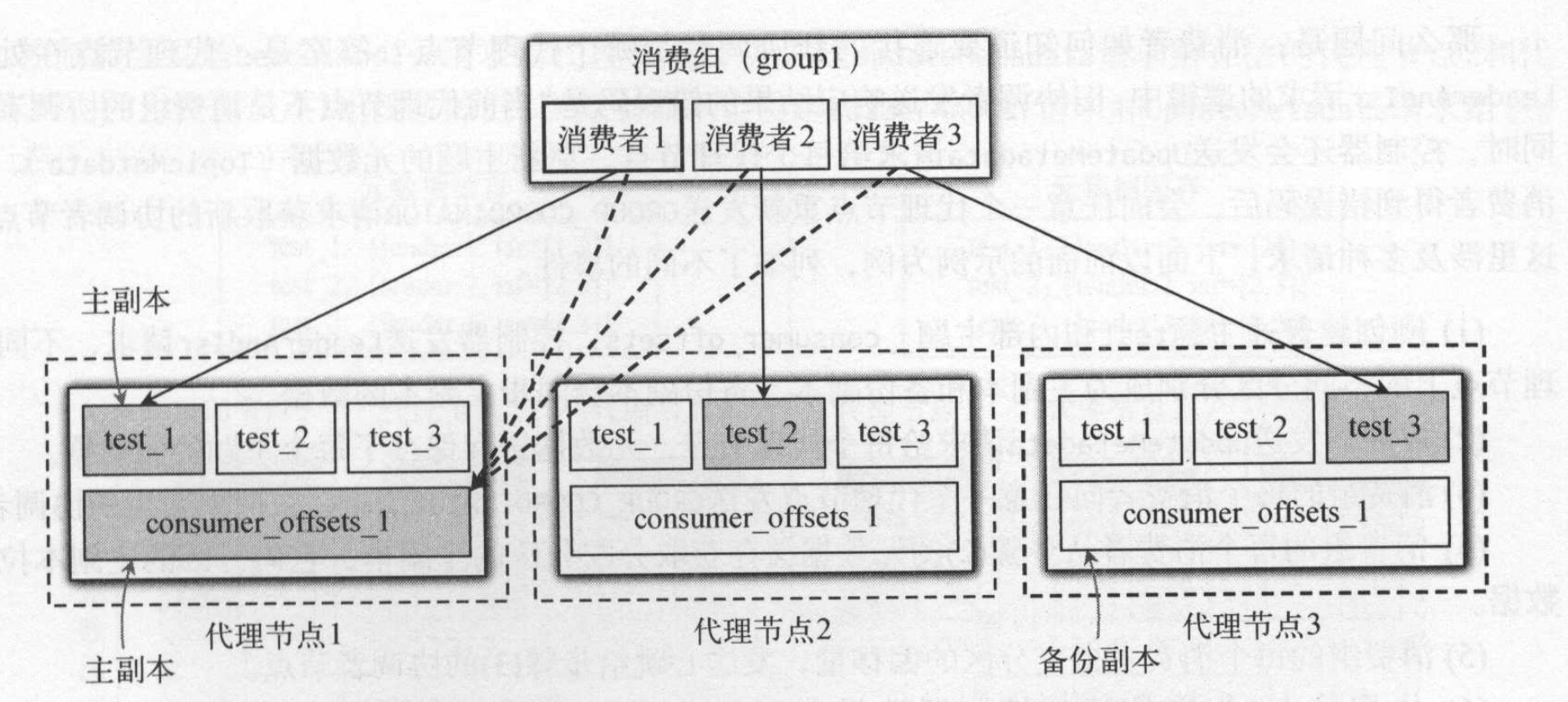
一旦协调者节点挂了,则会转移到其他节点上: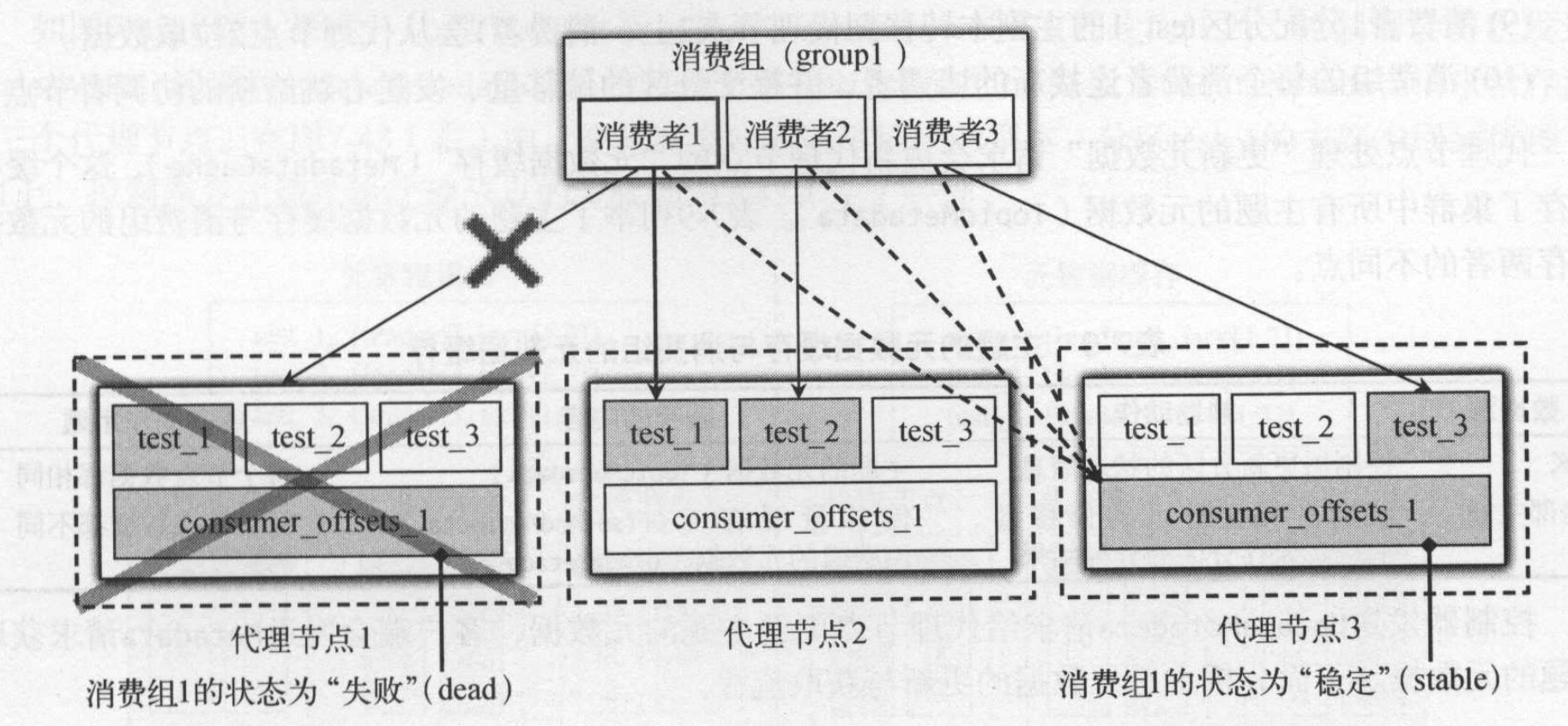
如图所示,如果节点1挂了,那么consumer_offsets_1的主副本转移到了代理节点3上。代理节点3成为了消费组新的协调者。当消费组的协调者发送故障时,消费组的每个消费者都需要连接新的协调者。
三. 分区平衡管理
3.1 消费者加入消费组
消费者在消费消息的时候需要先加入消费组,通过协调者给消费者分配partition。然后消费者再从这些partition上消费消息。
消费者加入组的大致步骤如下:
- 每个消费者都向协调者发送“加入组请求”,申请加入消费组。
- 协调者收集所有的消费者,以及它们的订阅信息。
- 协调者选举一个消费者作为客户端的主消费者。主消费者是第一个发送“加入组请求”的消费者,如果主消费者宕机则选择下一个消费者作为主消费者。
- 协调者向所有发送“加入组请求”的消费者返回响应结果,其中包含所有消费者的成员列表。
- 协调者将分区分配交给了主消费者,因此主消费者需要做额外的分区分配工作。并将计算完成后的分区结果发送一个“同步组请求”给协调者。
- 而普通消费者受到“加入组请求”的响应后,立即向协调者发送一个“同步组请求”。
- 不管是主消费者还是普通消费者,“同步组请求”就是为了获取分区分配结果。
- 协调者收到主消费者的分配结果后,将分区返回给每个消费者。
- 各个消费者收到结果后,将分区partition设置到消费者的订阅状态中,并重置心态定时任务。
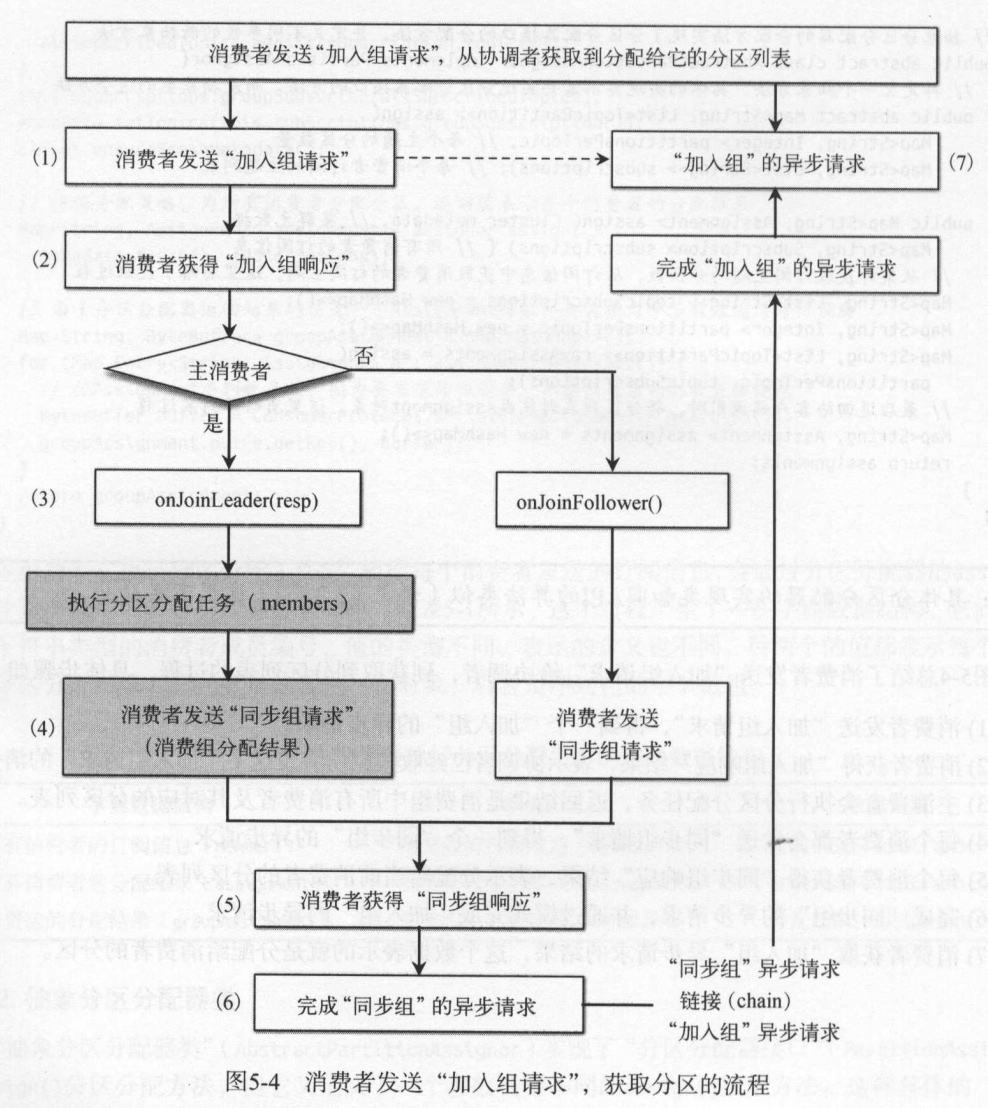
协调者不会直接分配分区,而是将分配分区的处理交给了主消费者。这样做的好处就是可以减少协调者本身的负担,但是缺点是客户端计算结果后,需要把分区结果同步给协调者,再由协调者将分区结果同步给各个消费者客户端。
如何选择主消费者?
通常选择第一个发送“加入组请求”的消费者作为主消费者。如果主消费者宕机则选择下一个消费者作为主消费者。
如何处理主消费者宕机?
不管是什么类型的消费者,都会按照心跳超时的方式处理,失败的消费者将被协调者从消费组移除,并触发再平衡操作,剩余存活的消费者需要重新加入消费组。
消费者如何得到分区结果?
每个消费者发送“加入组请求“后,会再发送一个”同步组请求“给协调者来获取分配的分区。普通消费者在发送”加入组请求后“立即发送一个”同步组请求“,而主消费者是在等分区分配完成后,带着分区结果发送一个”同步组请求“给协调者。
3.1.1 加入组请求和同步组请求
各个消费者向协调者发送”加入组请求“,协调者收集所有消费者消息后会给所有消费者响应。但是会根据不同的消费者的类型响应不同的内容:
- 返回给主消费者的响应结果是”所有消费者成员列表及其订阅的信息“。主消费者根据分区分配算法,给所有消费者分配分区。分配完成后,带着分配结果发送一个”同步组请求“给协调者。
- 返回给普通消费者的响应结果没有那些信息。普通消费者收到”加入组请求“的响应后,马上发送了一个”同步组请求“给协调者。这里采用了链式模式,将”同步组请求”的结果会作为“加入组请求”的结果返回给消费者。
消费者发送的“加入组请求”内容包含了:消费组编号、消费组成员编号、协议类型、协议内容(分配分区的算法)和元数据。加入组请求时,如果消费者成员编号未知,协调者会为其分配一个新的成员编号,然后创建消费者成员元数据,并加入到消费组元数据中,并将成员编号作为“加入组请求”的响应结果返回给消费者。如果消费者成员编号是已知的(一般是再平衡时),只需要更新已有成员的元数据即可。
消费者向协调者发送“同步组请求”的时候必须带上消费者的成员编号。协调者在发送“同步组请求”响应给消费者之前,先会把“消费者分配结果”以普通消息的形式持久化到内部主题(consumer_offsets)中。 如果协调节点出现故障需要进行故障迁移,新的协调者可以从consumer_offsets中读取持久化的消息,重建“消费组分配结果”。
3.1.2 主消费者执行分区分配
消费者发送的“加入组请求”内容包含了:消费组编号、消费组成员编号、协议类型、协议内容(分配分区的算法)和元数据。在分配分区的时候只能使用一个协议,因此协调者在收到所有消费者的信息后,同一所有消费者的协议,选择一个大多消费者都支持的分区分配协议。
消费者进行分区分配的算法有两种:
- RoundRobinAssignor
- RangeAssignor
RoundRobinAssignor
- 首先对所有的消费者按照消费者memberId排序。构成一个循环链。
- 对所有的partition按照topic和partition顺序排序。
- 然后遍历所有的partition,并已排好的顺序采用轮询的方式分配给消费者。
例如有两个消费者C0和C1, 都订阅了主题T0和T1, 并且每个主题都有三个partition。则产生了
- 首先对消费者排序得到:C0, C1
- 对partition排序: T0P1, T0P2, T0P3,T1P1,T1P2,T1P3
- 遍历所有的partition进行分配:
- 遍历T0P1时,开始轮询消费者,因为C0订阅了T0,则分配。 即 C0:T0P1
- 遍历到T0P2,此刻下一个消费者是C1, C1订阅了T0则分配给它。 即C0:[T0P1] , C1:[T0P2]
- 遍历到T0P3,此刻又轮到了消费者C0, 则分配给它。 即C0:[T0P1, T0P3], C1:[T0P2]
- 遍历到T1P1, 轮到消费者C1。即C0:[T0P1, T0P3], C1:[T0P2,T1P1]
- 遍历到T1P2, 轮到消费者C0。即C0:[T0P1, T0P3, T1P2], C1:[T0P2,T1P1]
- 遍历到T1P3, 轮到消费者C1。即C0:[T0P1, T0P3, T1P2], C1:[T0P2,T1P1, T1P3]
消费者发送“同步组请求”的内容包含:消费组编号、纪元编号、消费者成员编号、消费组分配结果(只有主消费者才会发送)。
3.2 消费者再平衡
消费者开启了一个“消费组再平衡监听器”,当消费者列表发生改变的时候协调者会通知消费者的再平衡监视器,让消费者重新加入消费组,进行再平衡操作。
“消费组再平衡监视器”只使用订阅模式的消费者API,如果是手动分配分区模式,则监视器不会起作用。
3.3 消费组元数据状态
消费组元数据管理了所有消费者的“成员元数据”以及消费偏移量,如上文所说这些都是以内部主题__consumer_offsets的方式进行存储。
消费组元数据除了以上数据外,还有一个非常重要的数据,就是消费组状态。消费组状态有4种:
- 稳定状态(stable)
- 准备再平衡状态(preparingReblance)
- 等待同步状态(AwaitingSync)
- 离开状态(Dead)
协调者在处理消费者发送的“加入组请求”和“同步组请求”时,都会依赖消费组的当前状态进入不同的分支。
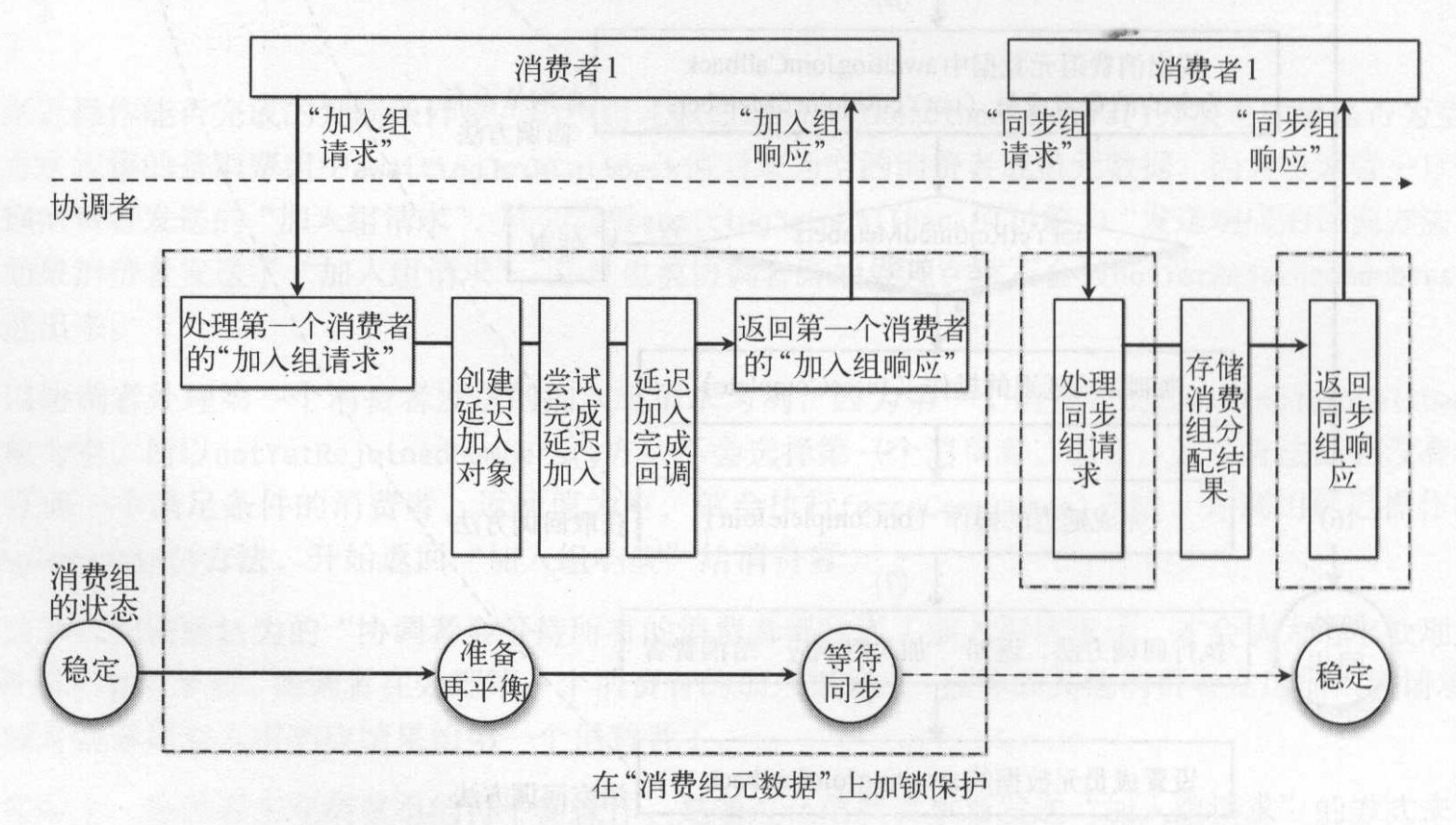
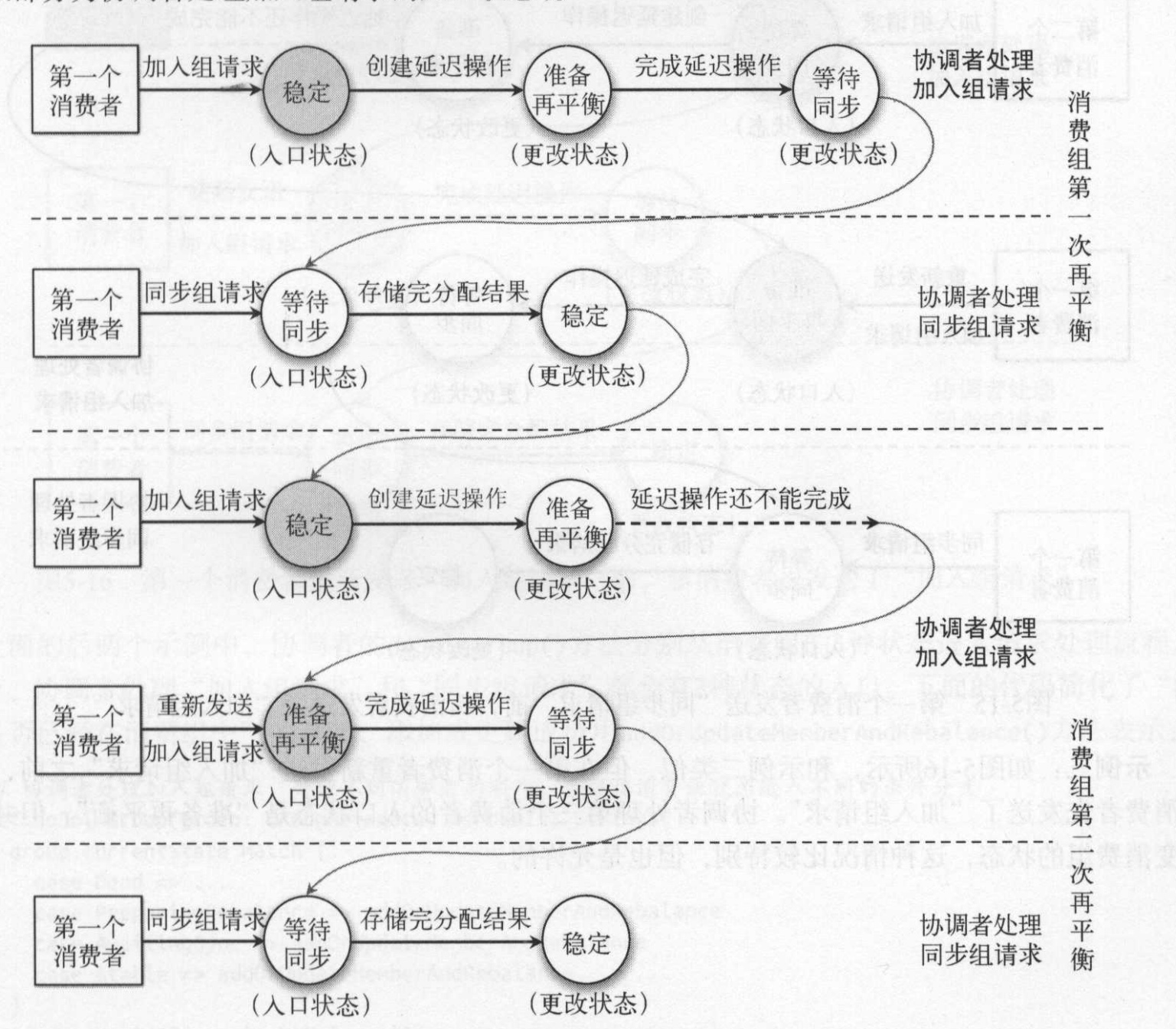
当只有一个消费者加入消费组时,具体流程:
- 协调者处理第一个消费者“加入组请求”, 会创建消费组的成员数据,并加入消费组元数据。这时候会进行加锁,避免同时处理多个“加入组请求”或“同步组请求”。
- 消费组初始状态为”稳定”状态,开始再平衡操作,将状态改为“准备再平衡”
- 创建一个“延迟加入组”的对象,并立即通过“延迟缓存”尝试完成刚创建的延迟操作。
- 目前只有一个消费者成员,notYetRejoinMembers()没有任何元素,满足“完成延迟操作”条件。
- 因为可以完成延迟操作,所以强制完成方法会调用延迟操作对象的onCompleteJoin()方法。
- 延迟操作对象在完成时的回调方法,会首先将消费组状态更新为“等待同步”
- 返回“加入组请求”响应给所有消费者。
- 释放同步锁。
- 主消费者处理分配分区后,将分配分区结果用“同步组请求”方式发送给协调者。
- 协调者处理同步组请求,需要加同步锁
- 存储消费组分配结果,将消费组状态改为“稳定“
- 返回同步组响应给所有消费者。
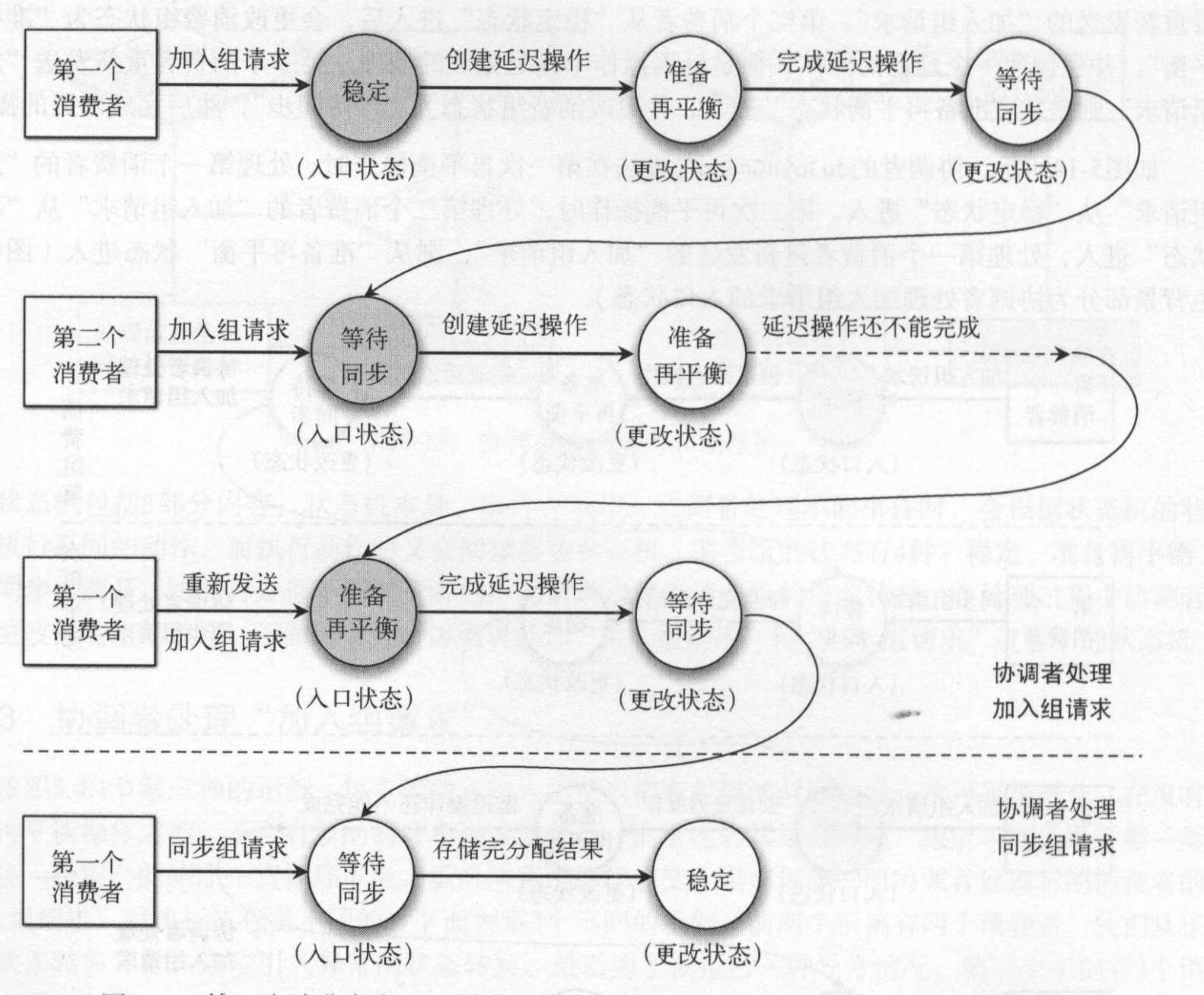
设置到消费组元数据的修改和查询操作过程都需要进行加锁,上面是显示一个消费者的处理流程。当存在两个消费者同时加入组时,首先消费者1加入组请求完成后,准备去执行分配分区算法,并将分配结果发送“同步组请求”给协调者。此刻正好有个消费组2要发起“加入组请求”。 消费组2的“加入组请求”和消费组1的“同步组请求”是互斥的,因为协调者做了加锁动作,因而有一下两种结果。如果“同步组请求”先到达,那么协调器处理“同步组请求”,将结果返回给所有消费者,并将状态改为稳定。如果是消费组2的“加入组请求”先到达,这时候就将消费组的状态改为“准备再平衡”,执行再平衡。下文对第二种情况进行描述。
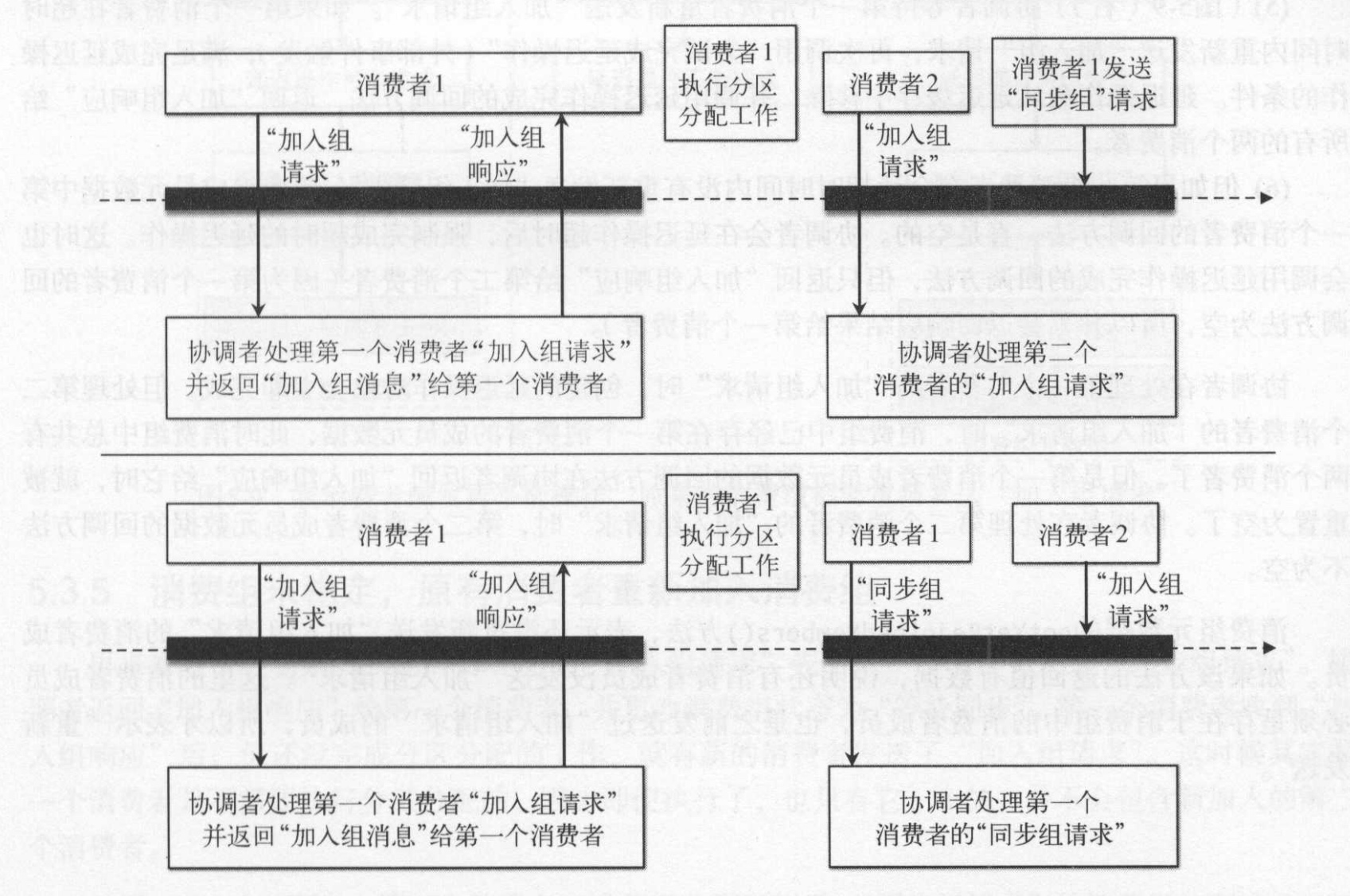
协调者在处理各个消费者的“加入组请求”或“同步组请求”的时候都会为其设置一个回调函数,当向该消费者响应“加入组请求”或“同步组请求”结果时将的回调函数设置为空。当消费组状态为“准备再平衡”时,需要等待所有消费者都加入消费组或发送“加入组请求”。协调者通过会检查所有的消费者的这个回调函数是否为空,来判断是否消费者都发送了“加入组请求”,如果存在回调函数为空的消费者则需要让其重新发送加入组请求。
如图所示,如果第一个消费组完成加入请求组后,第二个消费者加入消费组。因为处理每个消费者“加入组请求”都会将状态改为“准备再平衡”操作,检查有回调方法为null的,则让通知该消费者重新加入消费组。协调者只有获取所有消费者(保存在协调者中的消费组列表成员)的加入组请求后,才执行后续的动作。
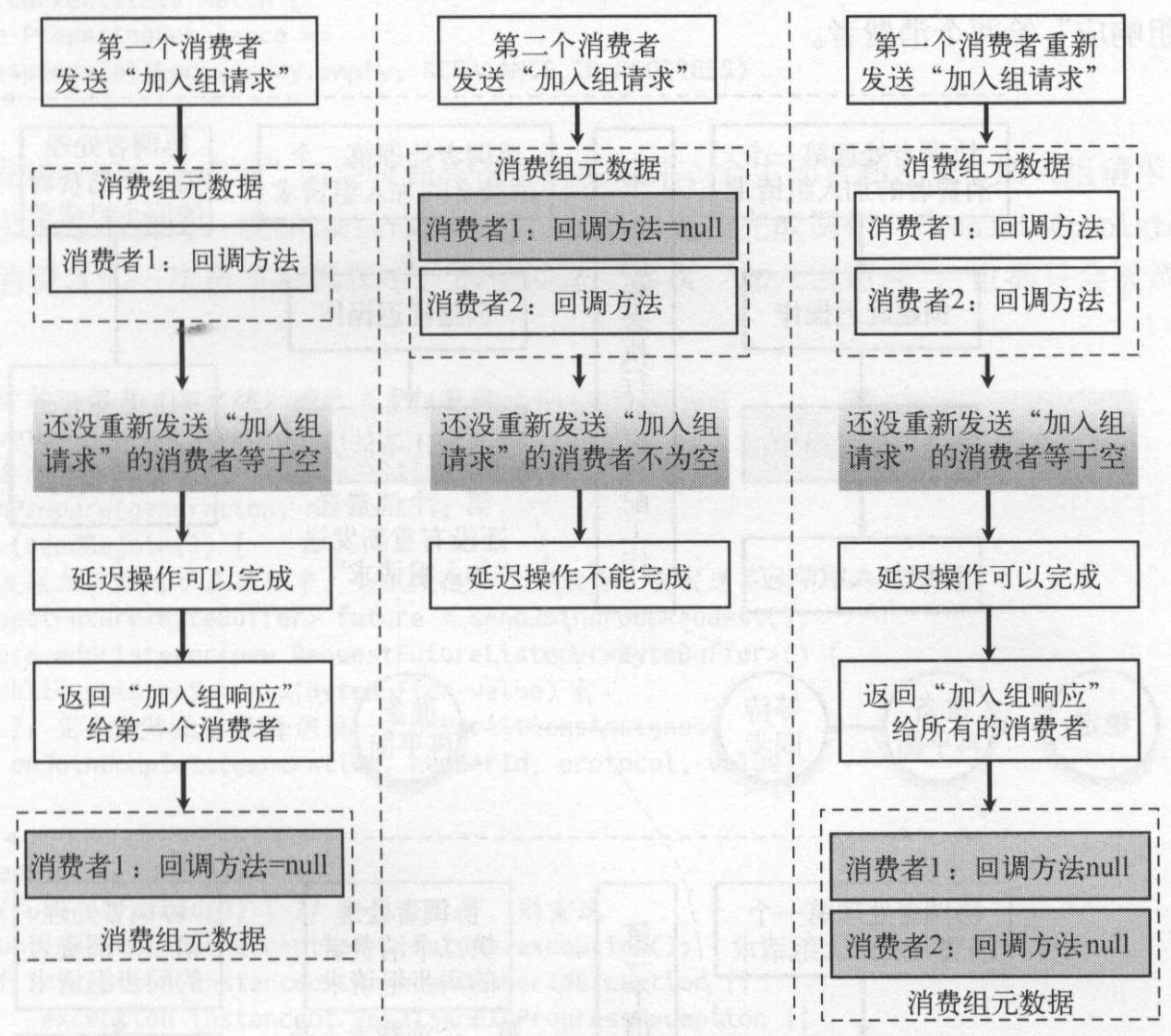
因此上面两个消费者不同时间加入会产生以下两种结果:
第一个消费者同步请求先到达
第二个加入组请求先到达
参考
- [1] Kafka 如何读取offset topic内容 (__consumer_offsets)
- [2] Kafka集群磁盘使用率瞬超85%,幕后元凶竟是它?
- [3]《kafka技术内幕》