一.概述
kafka采用了消费组的概念,使得kafka同时具备了发布-订阅模式和队列模式的两者的优点,保证同一个消费组里的一个消息被只能被一个消费者消费,提高吞吐量;另一方面保证了数据的容错性,可以不同消费组可以同时消费同一个消息。保证了一条消息可以被多个消费者消费。
采用pull的拉取方式,使得消费者自己控制消费进度。
1.1 队列模式
在讲kafka消费者实现的时候,我们先看看传统的队列模式,是如何从服务端获取消息。传统的队列模式有两种:
- 发布-订阅模式:同一个消息被多个消费者消费,实现多播。为了保证消息只被一个消费者消息,还需要引入一些同步机制。
- 队列模式: 每条消息只交付给一个消费者消费,提高数据处理的并行能力,多个消费者消费不同消息,但是如果消费者挂了会导致数据丢失。
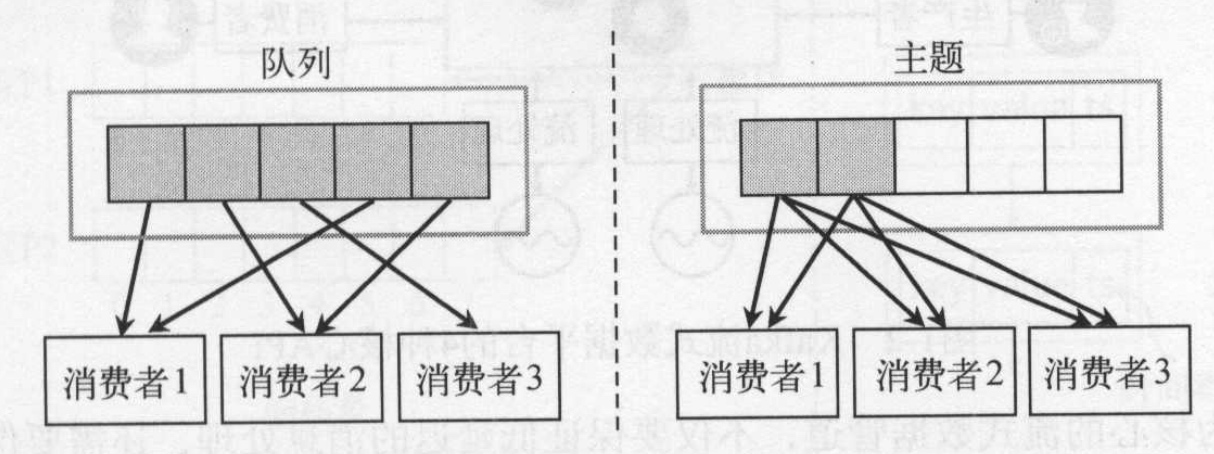
kafka则是利用的消费组的概念很好地结合两者模式的优点,因此kafka同时具备了发布-订阅模式和队列模式。
1.2 消费者获取消息形式
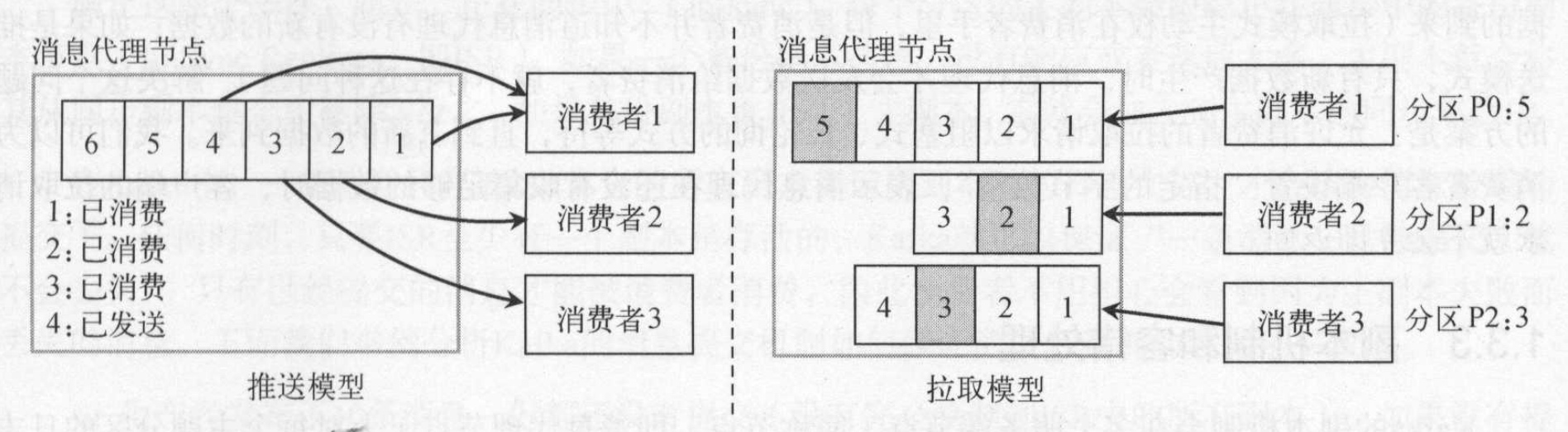
常用的消费者获取消息的形式有Push(推送模型)和Pull(拉取模型),两者各有利弊:
- 对于PUSH,broker很难控制数据发送给不同消费者的速度. 好处在于可以知道消费者数量和消费者进度。减少消费者对服务器的压力。
- 而PULL可以由消费者自己控制,但是PULL模型可能造成消费者在没有消息的情况下盲等,这种情况下可以通过long polling机制缓解,而对于几乎每时每刻都有消息传递的流式系统,这种影响可以忽略。 需要通过轮询的方式获取消息,因此增加了服务器brokers的压力。
NSQ、ActiveMQ使用PUSH模型,而Kafka使用PULL模型。因此需要消费者控制消费进度,根据进度去拉取。
消费者如何控制消费。
各个消费者维护了其消费的所有partition的消费进度offset, 消费者根据这个offset去服务端拉取数据,拉取数据后更新offset的值继续从服务器消费。消费者也可以修改offset的值来控制消费进度或进行重写消费等操作。
如果只有在消费者中保持offset信息,如果该消费者挂了,那么其他消费者如何消费其后续消息而不重复消费呢? Kafka会为每一个消费组分配一个协调器(也是一个broker服务器),协调者主要是为了维护消费组的消费进度并维护消费者的均衡负载。
在协调者中还保存了这个消费组对各个partition的消费进度, partition的消费进度则保存在协调者的_consumer_offsets。 消费者每次消费完消息后,会提交偏移量offset给协调者,协调者更新_consumer_offsets。 如果消费partition的消费者宕机,那么协调者会将该parition分配给其他消费者,其他消费者从_consumer_offsets或commit offset位置开始消费。
协调者如何维护各个消费者,这一部分后续有专门文章介绍。
消费者和ZK关系
- 消费者分配的分区从ZK中读取
- ZK存储了kafka内部元数据,而且记录了消费组的成员列表、分区的所有者。
- 每个消费者都需要在ZK的消费组节点下注册对应的消费者节点,在分配到不同的分区后,才开始各自拉取分区的消息。
二. 数据结构
kafka客户端最重要的数据结构是 SubscriptionState, 记录着当前消费者的订阅和消费情况:
1 | public class SubscriptionState { |
- subscription:存放了该消费者订阅的所有主题
- assignment:分配给当前消费者订阅和消费的partition。 记录着每个partition的消费拉取进度和提交进度。
1 | private static class TopicPartitionState { |
三. 流程和设计
消费者主要由 SubscriptionState、拉取线程Fetcher、分区分配(PartitionAssignor)、消费者的协调者(ConsumerCoordinator)组成。
- SubscriptionState是消费者的数据结构,记录了订阅的topic和分配分区的消费状态
- 分区分配(PartitionAssignor)是在开始时为消费者分配分区,指定消费的分区。
- 拉取线程Fetcher,负责从主副本的brokers中获取消息,并将消息存入到缓存队列中。
- 消费者的协调者(ConsumerCoordinator)是提交偏移量、维护消费组的消费进度、分配分区(再平衡)等操作。
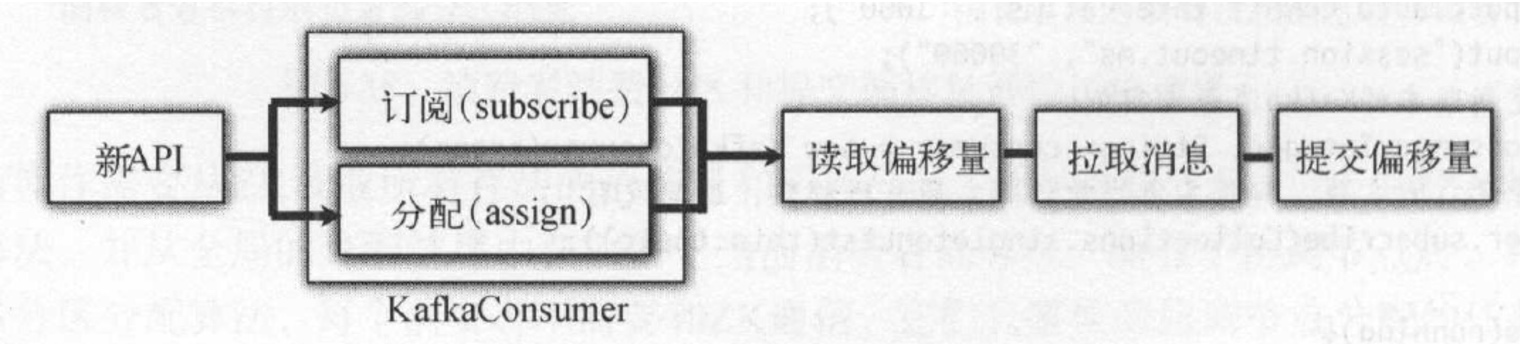
消费者的处理流程:
- 订阅topic和分配partition。 消费者客户端提供了两种消费方式:可以订阅主题topic或指定分配的partition,如果是订阅者需要则在后面会为客户端分配对应的partition。
- 消费者轮询处理:
- 轮询前工作,主要是加入消费组、获取分区
- 尝试从全局队列中获取已经拉取到的数据,如果没有则需要发送拉取请求和获取记录。如果有,则直接返回给用户处理
- 拉取器发送拉取数据请求:采用异步方式发送,如果成功则将结果写入到全局队列中。
- 消费者获取记录:采用轮询的方式等待全局队列中的消息
- 消费者消费消息:用户消息处理逻辑
- 提交偏移量: 提交偏移量后使得协调者知道该消费者的消费进度。
3.1 订阅Topic和分配Partition
kafka消费者主要提供了两种消费方式:
- 订阅主题方式:subscribe(topic), 这种方式需要客户端与协调者一起为该消费者分配一个partition消费。
- 手动分配分区方式: assign(partition), 用户直接指定了partition
3.1.1 手动分配分区方式
这种方式比较简单,一开始就确定了分区。根据用户指定的partition直接加入到TopicPartitionState的assignment数据结构中。 assignment内部是一个TopicPartition和TopicPartitionState的映射map.这种方式便于查找。
1 | @Override |
3.2.2 订阅主题方式
这种模式需要通过消费组协调之后才能确定分区,消费者拉取消息必须确保分配到了分区,有了分区以后后续的流程和分配方式流程一样。
因为分配的时候需要先加入组,或许消费者的信息。因此用户在执行subscription的时候没有开始分配parition。分配partition的过程留在后面的轮询中执行。
3.3 消费者轮询

kafka的轮询是将轮询前的准备工作放入进来,轮询前工作主要是加入消费组、获取分区。 将这部分放到轮询部分考虑到broker或消费者等出现宕机情况,导致集群出现了再平衡。那么此刻协调者需要重新给消费者分配新的分区,以实现再平衡。但是避免每次都进行轮询操作,kafka通过一些变量来控制是否执行轮询前准备工作。
1 | do { |
- 每次轮询获取一批消息
- 记录如果存在消息记录,则重新向客户端发送一个拉取消息请求。拉取过程是一个异步操作,因此不会阻塞。拉取器获取的消息会存入到缓存中,下次轮询的时候可以直接从缓存中获取。实现了用户的消息消费与拉取数据之间保持并行,提高性能。
- 轮询中还加入了超时概念,如果超过指定时间则从轮询中返回,不等待结果。
pollOnce 是真正的轮询部分:
1 | private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) { |
可以对pollOnce进行拆分,包括以下几个步骤:
- 轮询前准备工作。 主要包含了加入消费者、分配分区,及启动心跳检测线程
- 提交偏移量定时任务:如果到点则执行提交偏移量定时任务,默认5秒一次
- 心跳检测定时任务:如果到点则执行,默认也是5秒一次
- 发送拉取数据请求
- 获取拉取数据
1)轮询前准备
轮询前动作主要加入到消费组中,并获取分区。 只要第一次轮询已经消费者出现再均衡时需要进行轮询前准备,通过该过程得到消费者消费的分区。
- 消费者发送“加入消费者的请求”,想协调者申请加入消费组。
- 协调者接受消费者加入消费组
- 协调者等待其他消费组中其他消费者也发送“加入消费组的请求”。
- 协调者执行分区分配算法为所有分配分区。最简单的是round-robin算法,即轮询分配方式。
- 消费者同步等待结果,等待协调者返回分区给消费者。 这里必须是同步的,后面的过程是依赖这个结果。
因为后续的操作都需要依赖分区,因此这个地方必须同步等待结果后才能执行后续工作。
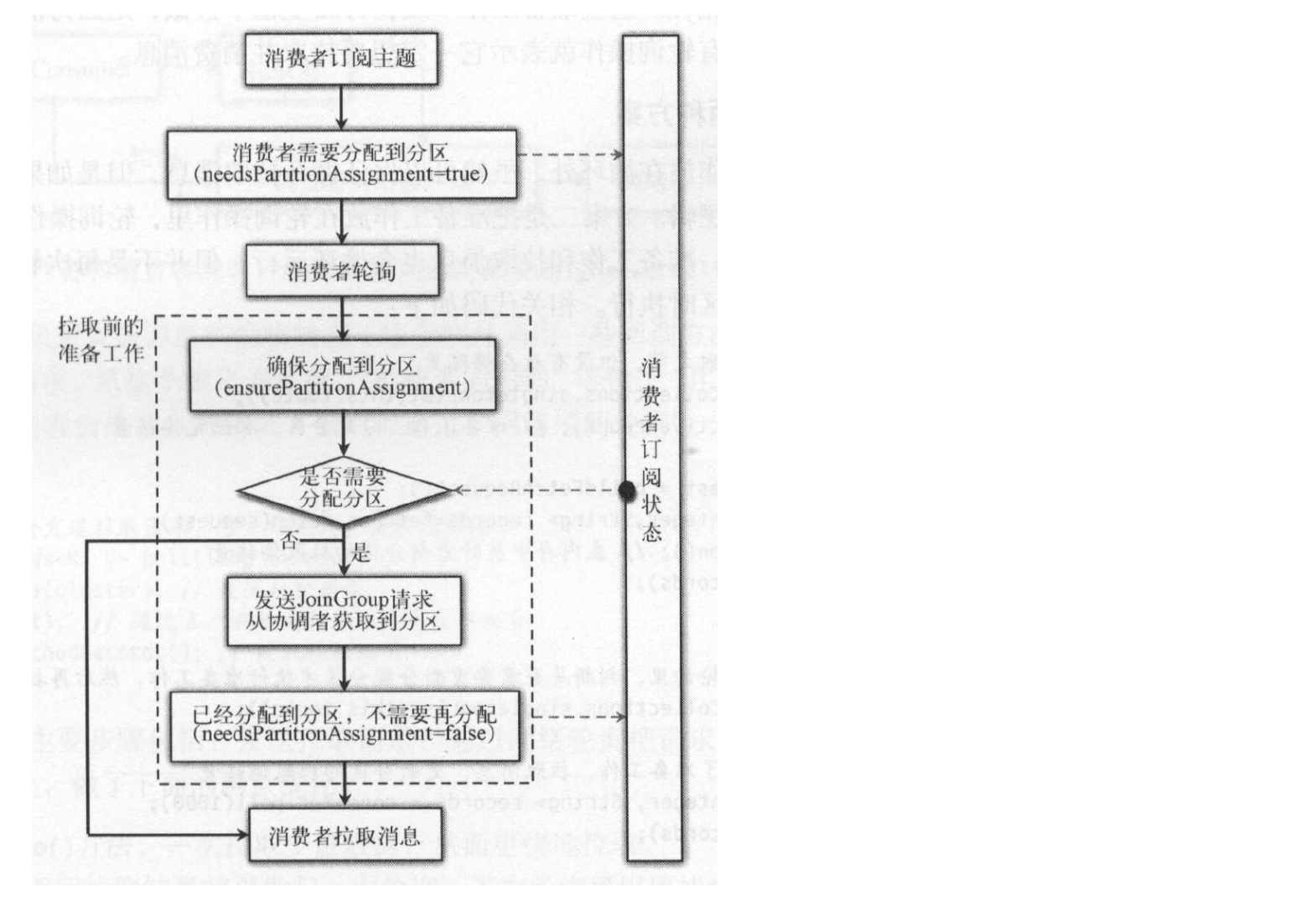
消费者只有在再平衡的时候才需要重新加入消费组,消费者在启动的时候会向ZK注册不同事件的监听器,当注册事件发生变化时会触发ZKReblanceListener的再平衡操作。再平衡操作采用变量形式来控制,避免了额外的通讯开销,直接通过内存修改控制操作,不需要与其他组件交互,更加高效。
在这个过程同时开启了心跳检测功能。
2)性能优化
- 循环调用pollOnce()方法,一次拉取少量数据,从而更快地拉取
- 用户处理和消息获取采用并行模式
通过并行模式提高系统性能。串行和并行的区别: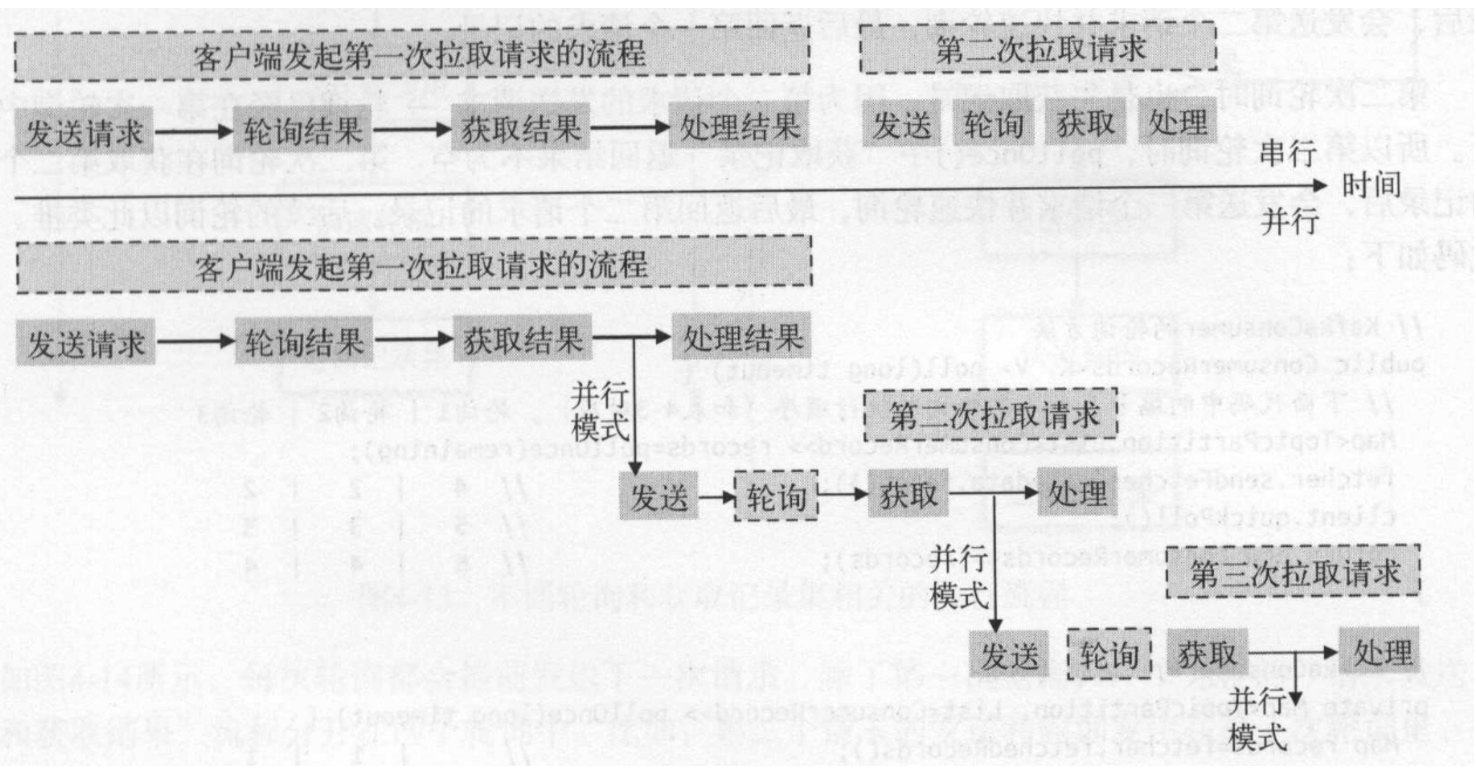
串行模式是在客户端处理完数据以后再次去发送获取下一批消息,所以用户处理消息逻辑和kafka客户端获取数据逻辑之间串行执行。而并行模式是在用户处理结果的时候就发送一个拉取数据请求,这样减少下一次获取数据的等待时间。当处理完数据后,想获取下一次数据时kafka已经为其准备好。并行模式是基本逻辑:
- 第一次的时候完成发送、轮询获取后,再发起第二个请求(发送请求、轮询,发送请求和轮询采用异步,无需等待结果)
- 第二次以后首先获取结果,然后发送下一批的请求(发送请求采用异步方式)
异步发送和轮询得到的结果会发在拉取器Fetcher的一个阻塞队列中,每次获取时只需要从这个阻塞器获取即可。
并行模式方式:
3)拉取器拉取数据
为了减少客户端和服务器集群的网络连接,客户端不是以分区为粒度和服务器交互,而是以服务器节点为粒度。如果分区的主副本在同一个节点上,应当在客户端先把数据按照节点整理好,把属于同一个节点的多个分区作为一个请求发送出去。
发送消息过程和生产者一样,都是按主副本目标节点分组发送,减少了网络操作,提高处理能力。
拉取请求
调用send()方法实际上并不会将请求通过网络发送到服务端,只要等到轮询的时候才会真正发送出去。这也是消费者轮询时在发送请求后,需要调用客户端轮询方法的原因。
1 | private Map<TopicPartition, List<ConsumerRecord<K, V>>> pollOnce(long timeout) { |
sendFetches方法中调用了client.send(), client.send()方法不足被阻塞,而是返回一个异步对象。为了能够处理服务器返回的响应结果,在返回的异步对象上添加一个处理器拉取响应的监听器,当收到服务器的响应结果时,监听器里的回调方法将会被执行。
处理拉取响应
在发送拉取请求的时候注册了一个监听器,当收到响应结果的时候就会回调监听器的方法。拉取器的数据处理就是在这个监听器中。主要是将服务端返回的数据转换为客户端数据格式,并存入到一个完成的阻塞队列completedFetches中。下次直接从队列中获取就可以了。
4) 消费者获取记录
在用户处理消息之前需要需要获取数据,如上面介绍在拉取数据的时候已经将消息存放到了全局变量completedFetches中,因此每次从这个阻塞队列中获取就可以。如图所示: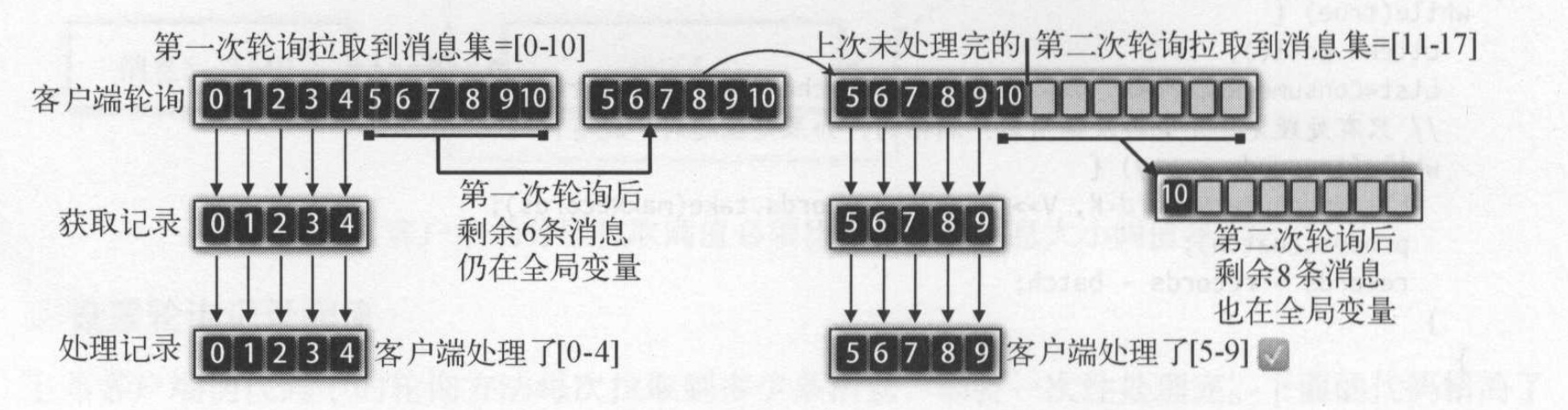
获得拉取数据后,更新订阅状态分区的拉取偏移量信息,即position。拉取器还做了以下几点优化:
- 一次轮询发送两次拉取请求,必须确保第一个请求获取到结果后,才允许发送第二次请求。
- 客户端轮询时可以设置每个分区的拉取最大阈值和最大记录数,防止客户端处理不了。
- 如果分区的记录集没有被客户端处理完,新的拉取器请求不会拉取这个分区。
5)消费消息
用户处理消息,这块是用户的实现逻辑。 因为心跳检测任务是在轮询过程进行判断和执行,如果消费者处理逻辑复杂,一批消息要处理很久,那么就会影响消费者和协调者之间的心跳检测。因此需要减少消费者处理复杂度,或者单独起一个线程处理。
4)提交偏移量
提交偏移量有两种形式,一种是用户自己手动提交,另一种是自动提交。自动提交方式采用定时任务方式实现。
提交偏移量需要使用协调者,提交时调用协调者的相应方法即可,将拉取偏移量提交到协调者中。
三. 消费者的网络客户端轮询
kafka消费对象KafkaConsumer的轮询方法通过拉取器(Fetcher)发送拉取请求,会调用消费者网络客户端对象(ConsumerNetworkClient)的发送请求方法send()和网络轮询poll(). 调用发送方法send()以后,一定要调用轮询方法poll(), 因为发送方法只是将请求暂时存放到unsent变量,只有调用轮询才会将unsent的请求真正发送到目标节点。
kafka客户端采用了组合、适配器、链式模式的组合为kafka客户端提供了一个功能强大的异步调用实现,该方式灵活可拓展。客户端请求对象包含了一个回调处理器,在客户端请求完成并受到结果后就回调这个处理器。
为了完成这个异步处理的逻辑,kafka使用了以下几个重要结构来完成:
- RequestCompletionHandler:请求完成回调处理器,这个只是定义了一个接口。提供了回调方法。
- ClientRequest:客户端请求,包含了一个处理完成后的回调处理器RequestCompletionHandler
- RequestFuture: 对异步结果进行包装,可以对异步结果做多种操作。
- RequestFutureCompletionHandler: 异步请求完成处理器,结果处理交给了RequestFuture,方便引入监听器。
- RequestFutureListener: Future结果的监听器,负责处理RequestFutureListener得到结果后的一些操作
- pendingCompletion 异步请求完成处理器阻塞队列,ConcurrentLinkedQueue
pendingCompletion。
3.1 请求完成回调处理器
1 | // 回调处理器 |
以上定义了两个基本类,在请求的时候先将请求和回调处理器包装为ClientRequest,调用客户端进行发送send()。 在调用client.poll()进行轮询得到结果resonse的时候,调用其”请求完成回调处理器”的onComplete()方法。这种方式实现伪代码如下:

这种方式的调用过程可以用以下图来表示: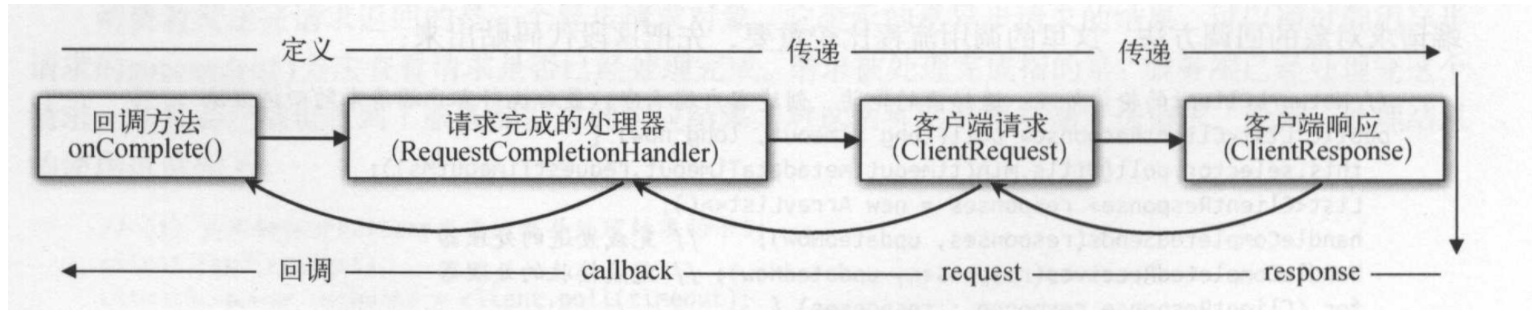
3.1 异步请求完成回调处理器
虽然上面结构已经可以完成同步转异步操作,但是这种方式拓展性比较差。比如某一个返回的结果中需要多种处理,那么只能在onComplete中增加新的逻辑。RequestFutureCompletionHandler实现了RequestCompletionHandler接口,并组合了RequestFuture对象。其结构如下:
1 | private class RequestFutureCompletionHandler implements RequestCompletionHandler { |
其处理流程基本和上面那种方式一样,不同的在于调用onComplete后,处理器没有直接处理结果,而是将当前对象加入到了一个阻塞队列ConcurrentLinkedQueue
1 | public class RequestFuture<T> implements ConsumerNetworkClient.PollCondition { |
这种方式有两种使用方式:
和原来逻辑一样,覆盖了onComplete方法:

使用监听器

这种方式的调用逻辑是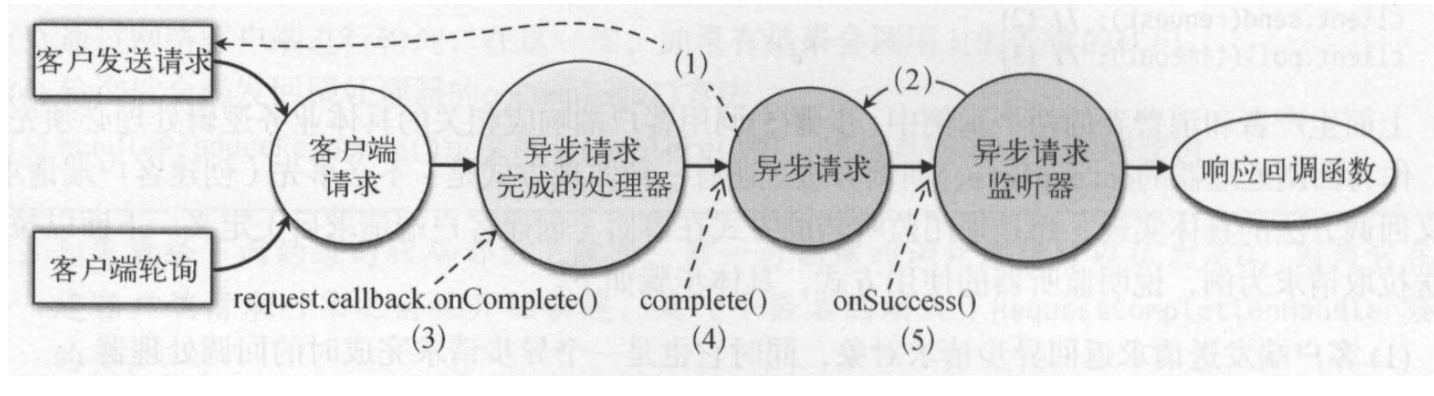
kafka的拉取发送采用的就是第二种方式,实现逻辑本部和之前说那种处理方式一样。因为加了阻塞队列和监听器,因此在poll中加入了以下逻辑:
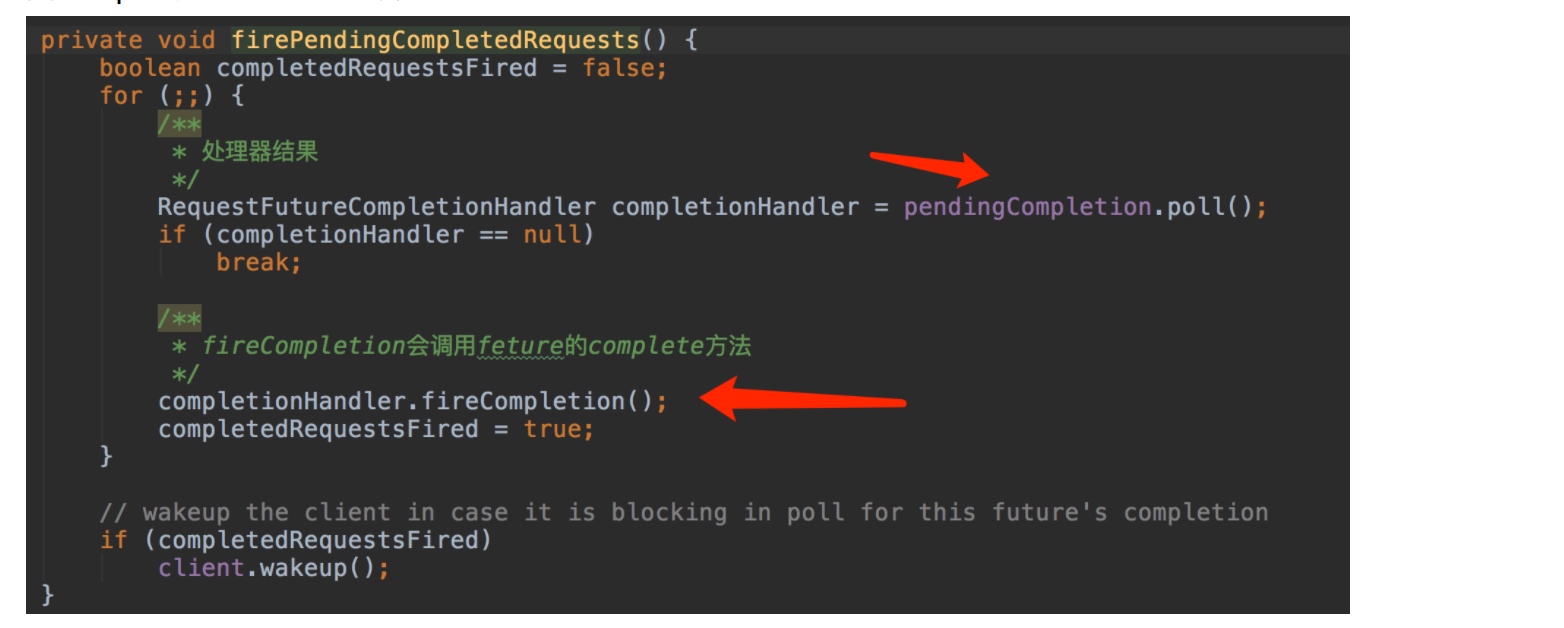
- 从队列中获取一个异步请求完成处理器
- 调用这个处理的fireCompletition,这个方法会调用requestFeture的complete方法。进而遍历所有的监听器并调用onSuccess方法
四. 定时任务
kafka的定时任务设计和redis很像,在一个主轮询函数中判断定时任务是否到期,如果到了则执行。主要有三个特点:
- 定时任务是通过消费者的轮询动作触发的,如果没有轮询,就不会执行定时任务。
- 定时任务也会发送请求给服务端,并且在收到响应结果后需要做一些具体的业务处理。
- 如果上一次的任务没有完成,定时任务就不会启动新的任务。
存在两个定时任务:
- 心跳检测:每隔10秒发送一次
提交偏移量任务:每隔5秒提交一次
这些定时任务都是在轮询中执行和判断。如果当前时间大于定时任务的截止时间,则执行定时任务。并重新计算和设置下次定时任务时间。
4.1 心跳检测
消费者后端有一个线程专门负责心跳检测。
4.2 提交偏移量任务
消费者消息处理语义包括3种:
- At least once: 至少一次 — 消息绝不会丢失,但有可能重新发送。
- At most once:最多一次 — 消息可能丢失,但绝不会重发。
- Exactly once:正好一次 — 这是人们真正想要的,每个消息传递一次且仅一次。
至少一次
先处理消息,最后再保存消费进度。可以采用手动调用同步提交偏移量模式。
最多一次
先保存消息进度,然后才处理消息。通过设置自动提交,并在较短的时间内自动提交。
正好一次
在保存消费进度和保存消费结果之间,引入两阶段协议,