一. 概述
生产者要发送消息,不是直接发送给服务端,而是先在客户端把消息放入到消息队列中,然后由一个消息发送线程从队列中拉取消息,以批量的方式发送消息给服务端。kafka生产者包括以下几个重要部分:
- 记录收集器(RecordAccumulator): 负责缓存生产者客户端消息。
- 发送线程(sender): 负责读取记录的批量信息,通过网络发送给服务端。
- 选择器(Selector): 处理网络连接和读写处理。
- 网络连接(NetworkClient): 负责客户端网络请求。
消息发送过程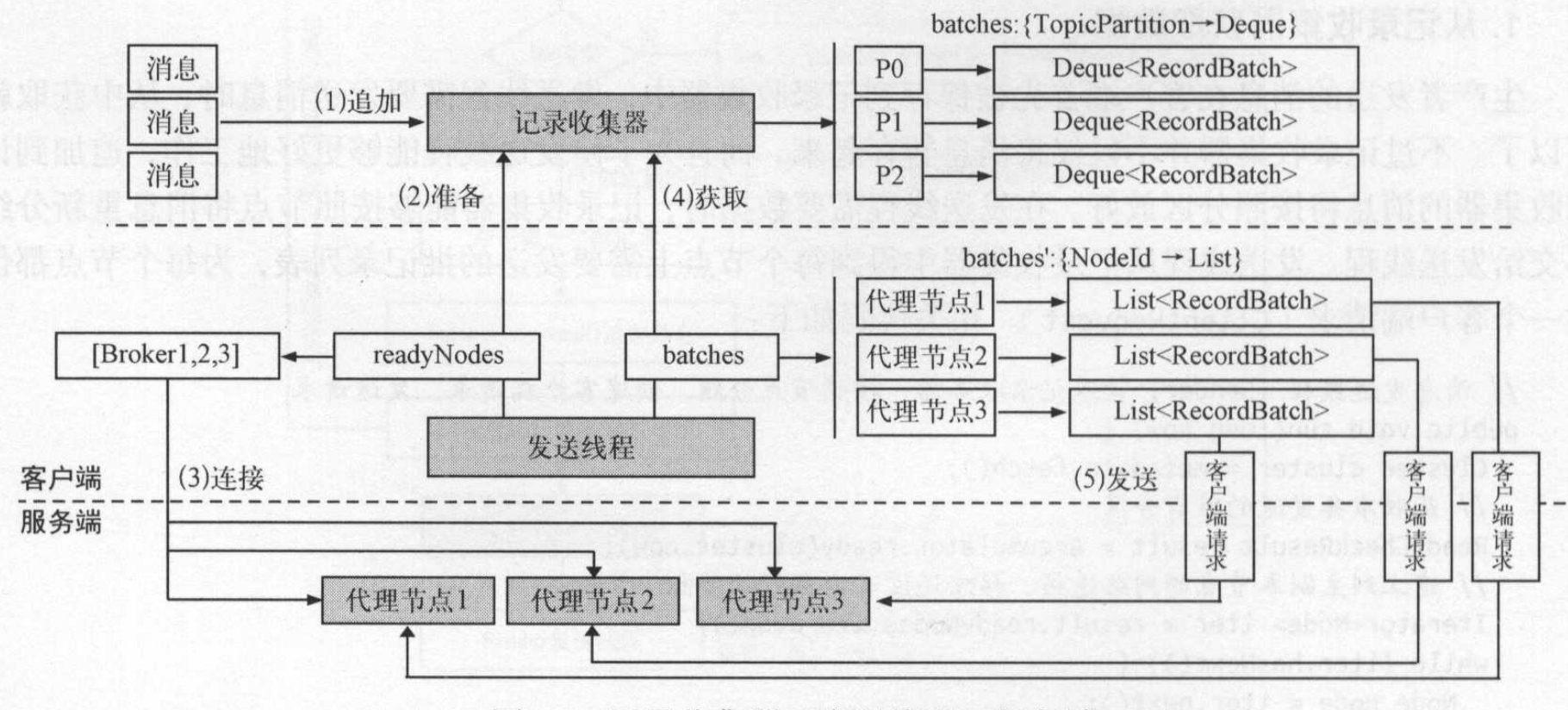
生产者发送消息大致过程如下:
- 序列化消息的key和value.
- 选择分区方式。kafka根据key进行自动均衡分配:
- 如果key存在则根据key求散列值并和partition数据求余数。
- 如果没有key则采用round-robin方式分配。
- 指定发送消息方式: 发送消息方式有两种,异步或者同步。
- 记录收集器RecordAccumulator收集记录:消息不知直接发送出去,而是先将消息存在记录收集器中。
- 将消息按分区的方式追加到记录收集器RecordAccumlator中.
- 发送线程Sender从记录收集器获取记录:收集器的记录达到一个批次数量或者超过一定时间,那么从里面获取消息按批次发送。
- 从记录器获取时,记录器对批数据重新组合,重新按主副本节点进行分组。见上图(4)
- 选择器选择网络连接进行发送
二. 实现
2.1 选择一个分区方式
如果没有提前在创建topic的时候指定分区,默认分区为1个(可配置),kafka的broker中提供了一个默认分区数量的配置:
1 | # 每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖 |
kafka消息是按分区消费的,一个分区分配给一个消费者,多个分配可以分配给多个消费者,这样通过分区方式可以提高消息的吞吐率,提高并行处理效率。生产这样也可以通过分区方式并行的发送消息,提供了消息的写和发送效率。因此采取分区的优势有:
- 提高了生成者发送的性能,可以并行发送
- 提高吞吐率,提高消费者消息消费性能
- 保证消费者消费消息的有序性
为什么在消息生产者中选择消息的分区?
因为只有选择了分区,我们才知道要把消息发送到哪里。kafka提供了两种分区方式:
- 先对key进行散列,再与分区的数量取模运算得到一个分区编号。
- 如果没有key,则会采用round-robin方式,通过计数器轮询均衡地分发到不同的分区
1 | public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) { |
2.2 指定发送消息方式
kafka发送消息提供了两种方式:
- 同步:调用send的返回Future时,需要立即调用get。在get方法中一直阻塞直到获取返回结果。
- 异步:提供一个回调,调用send后可以继续发送消息而不用等待。当有结果返回时,会自动执行回调函数。用户在操作的时候指定回调函数即可。
kafka源码的demo中已经提供了同步和异步的两种使用方式, 同步:
1 | producer.send(new ProducerRecord<>(topic, |
同步方式直接调用get阻塞获取。
异步方式:
1 | producer.send(new ProducerRecord<>(topic, |
异步方式则传入一个回调处理器DemoCallBack,等发送成功以后回调该回调处理器。
2.3 记录收集器RecordAccumulator收集记录
生成者发送的消息先是在客户端缓存到记录收集器(RecordAccumulator)中,等到一定时机再由发送线程sender批量发送到kafka服务集群。生产者每发送一条消息,都会向记录器追加一条信息,追加方法会返回记录器是否满了;如果满了则开始发送这一批数据。
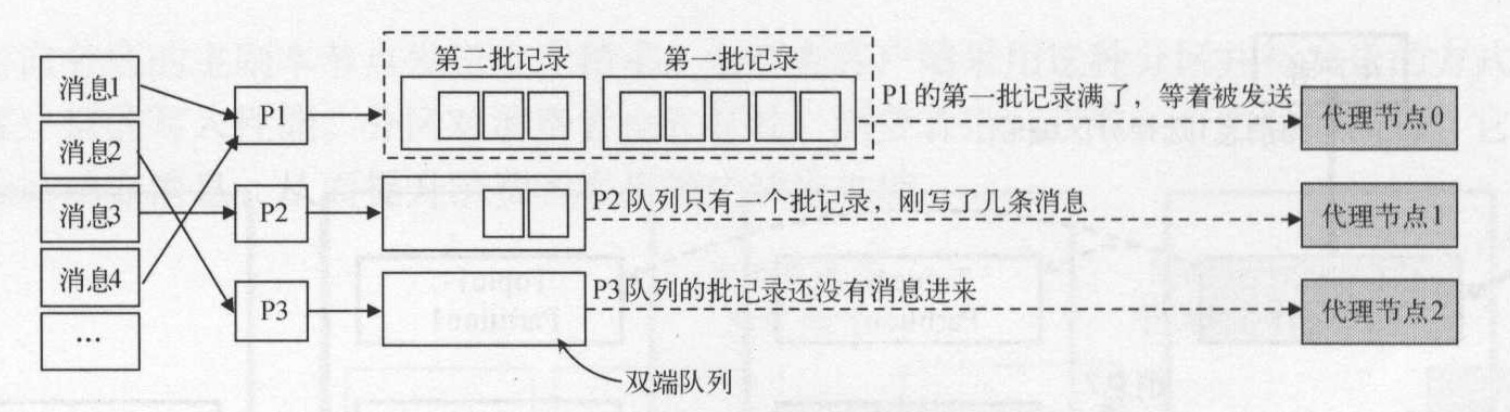
每一个分区partition都有一个双端队列来缓存消息。 从一端写入消息记录,发送线程从另一端获取消息记录。记录收集器(RecordAccumulator)会为每个分区提供一个缓存队列,每个缓存队列中按一个批次记录进行存储,即每个批记录是缓存对列的一个元素,而不是把一个消息当做存储单元。如果一个批次记录没有写满则继续往该批次记录中写数据。如果一个批次记录已经满了,则生成一个批次记录对象,用于存放新的消息数据。一旦分区队列中的有批满了,就会通知发送线程发送到分区对应的节点。如果批次没有满,发送线程则继续等待。如图所示:
1 | /** |
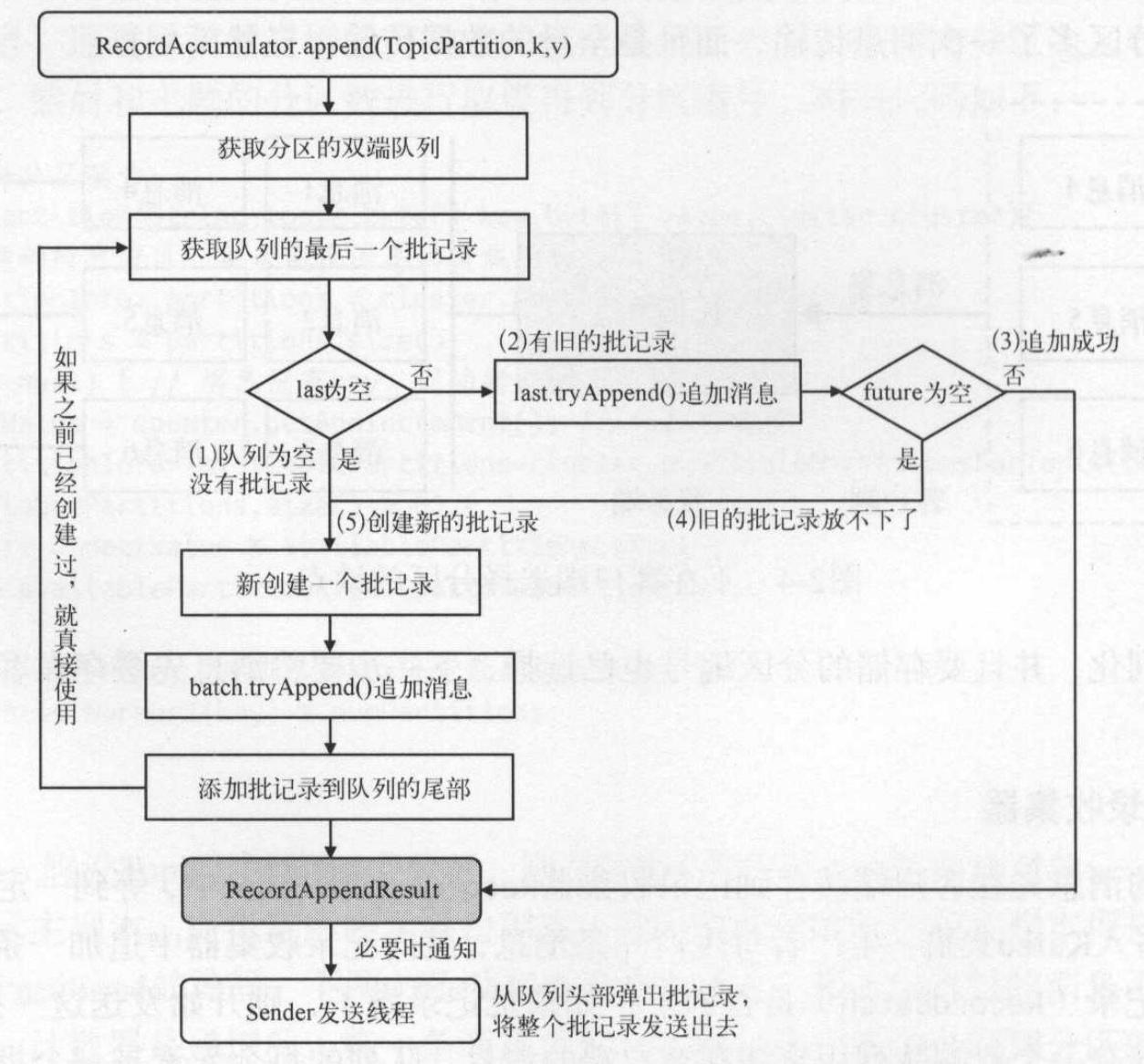
向记录收集器追加消息的时首先会获取该partition所属的队列,然后取队列中的最后一个批次记录:
- 如果队列中不存在批记录或者上一个批记录已经写满,应该创建新的批记录并加入队尾。
- 先创建的批次最先被填满,后创建的批记录表示最新的消息批记录。
追加消息时总是往最新的批记录中写消息。
其逻辑如图所示:
2.4 发送线程Sender从记录收集器获取记录
消息发送有两种方式:
- 按照分区直接发送。 即每一次发送一个分区的数据给分区对应的目标节点。kafka的采用多分区方式,因此可能会有多个分区数据都在一个节点上,导致向同一个分区发送多次请求。
- 按照分区的目标节点发送。对分区数据进行整理,将属于同一个brokers的分区数据一起发送过去。这样可以提高网络性能,减少网络请求。kafka采用的就是这种形式。
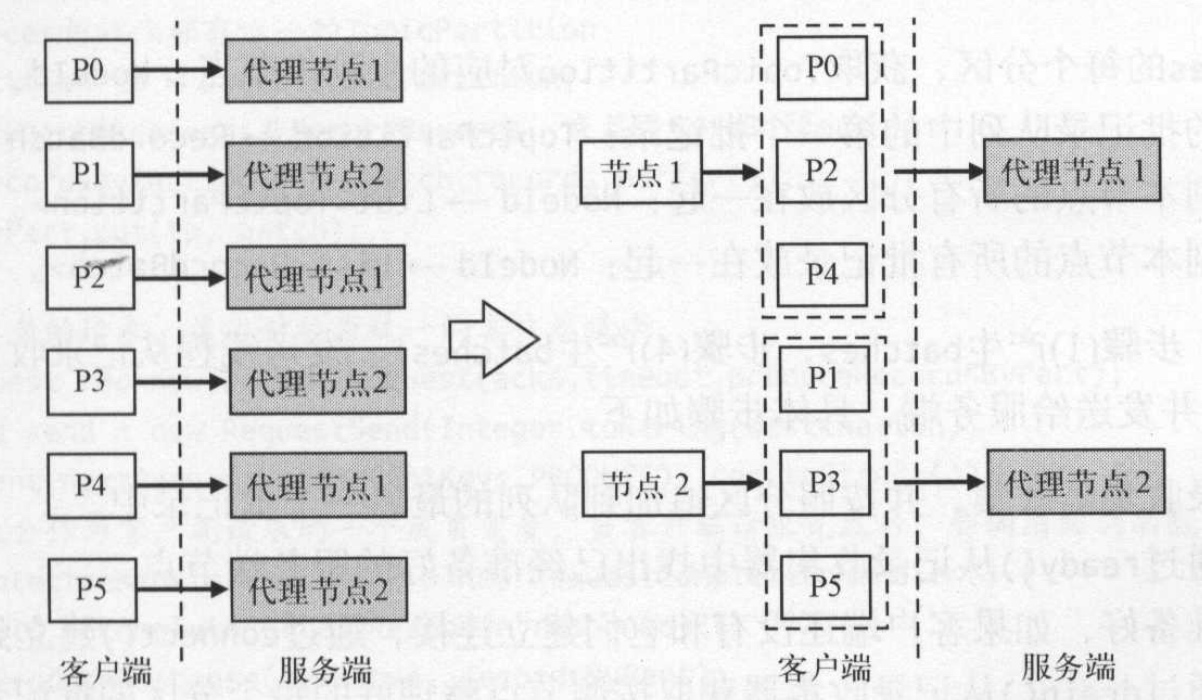
如上图所示,左边是按分区发送发送,右边是采用按目标节点方式发送。按目标节点方式发送极大减少了网络传输次数,提高了网络传输效率。
kafka采用了按照分区的目标节点方式进行发送,要求消息是按brokers方式进行分组,然后将属于一个brokers的消息一起发送出去。而收集器采用的是按分区进行分组的方式,为每个分区分配一个缓存队列,每次向收集器追加消息的时候存放了这个分区对应的批记录中。为了实现按目标节点分组的特性,记录收集器RecordAccumulator在获取消息时内部对消息进行了重新分组,使得获取的数据是按目标节点进行分组,便于发送者发送。
客户端使用一个发送线程Sender不断迭代获取记录收集器RecordAccumulator的批次记录,获取每个主副本节点对应的批记录列表,每个批记录对应一个分区。 然后根据主副本节点,将该节点对应的批记录列表发送出去。
1 | /** |
2.5 选择器选择网络连接进行发送
首先sender会为每个节点创建一个客户端请求对象,因为获取的数据是指定目标节点的批次列表,所以需要先为这些批次列表转换成分区到字节缓冲区的字典结构。 将数据存入到缓冲区,在发送时直接从该缓冲区拷贝到网络缓冲区中,实现内存的零拷贝,提高了性能。
发送线程没有真正发送消息,它只是从记录收集器中获取要发送的消息,根据消息创建网络请求对象,然后将网络请求对象交给(NetworkClient)发送出去。
NetworkClient对象管理了客户端和服务端之间的网络通信,包括连接的建立、发送客户端请求、读取客户端响应。
NetworkClient提供了三个方法:
- ready():从记录器收集器获取准备完毕的节点,连接准备好的节点。主要是调用selector.connect()方法建立到目标节点的网络连接。
- send():为每个节点创建一个客户端请求,将请求暂存到节点对应的通道中。send方法将客户端请求加入到inFlightRequests列表,然后调用selector.send()方法。这一步仅仅是暂存到节点对应的网络通道,没有真正发送。同一个客户端如果上一个客户端请求还没有完成,则不允许发送新的客户端请求。inFlightRequests列表则存储了还没有收到响应的客户端请求。在收到响应后会从inFlightRequests列表中删除。
- poll():轮询动作会执行真正的网络请求,比如发送请求给节点,并读取响应。轮询过程不仅会发送客户端请求,也会接受客户端响应。客户端请求发送后会调用handleCompletedSends处理已经发送完成的请求。客户端接收到响应后会调用handleCompleteReceives处理已经完成的接收。其中一个逻辑是将请求从inFlightRequests列表移除。
kafka客户端网络请求采用了Selector模式,即使用了Java NIO。 Java NIO有三个主要的概念:
- SocketChannel客户端网络连接通道。底层字节数据的读写都发生在通道上,通道器会和缓冲区一起作用。从通道读取消息时需要先构造一个缓存区buffer,调用channel.read(channel)将通道的数据写入缓冲区;将数据写入通道时,也需要先建立缓冲区,调用channel.write(channel)将缓冲区的每个字节写入通道。
- Selector选择器。发生在通道上的所有事件有读和写,选择器会通过选择键的方式监听读写事件的发生。
- SelectorKey选择键。将通道注册到选择器上,会返回一个选择键channel.register(selector),这样可以将通道和选择器关联。当读写事件发生时,可以通过选择器得到对应的通道,从而进行读写操作。
ready()
从记录器收集器获取准备完毕的节点,连接准备好的节点。主要是调用selector.connect()方法建立到目标节点的网络连接。
selector.connect()方法会创建客户端指定到远程服务器的网络连接,连接动作使用java的SocketChannel对象完成。 Kafka没有直接使用SocketChannel,而是将SocketChannel上面包装成KafkaChannel,并使用key.attach(kafkaChannel)将选择键和Kafka通道关联起来。当选择器轮询的时候,通过key.attachment()获取绑定到键上的Kafka通道。
选择器键还维护了一个节点编号到Kafka通道的映射关系,便于根据客户端节点获取Kafka通道。通道是复用的,如果发送的请求节点之前已经请求过,则在channels中存放了KafkaChannel,则直接根据节点编号获取KafkaChannel,否则创建一个。这样可以减少通道的创建开销。
1 |
|
send()
调用Selector.send的时候会调用KafkaChannel的setSend(send)方法。如果一个Kafka通道上还有未发送成功的Send请求,则后面的请求就不能发送,这里便不能设置成功,会抛异常。即客户端一个Kafka通道,一次只能发送一个Send请求。在setSend(Send)方法中注册了写事件。
poll()
poll方法会不断循环和监听网络事件,根据不同的时间做不同的处理:
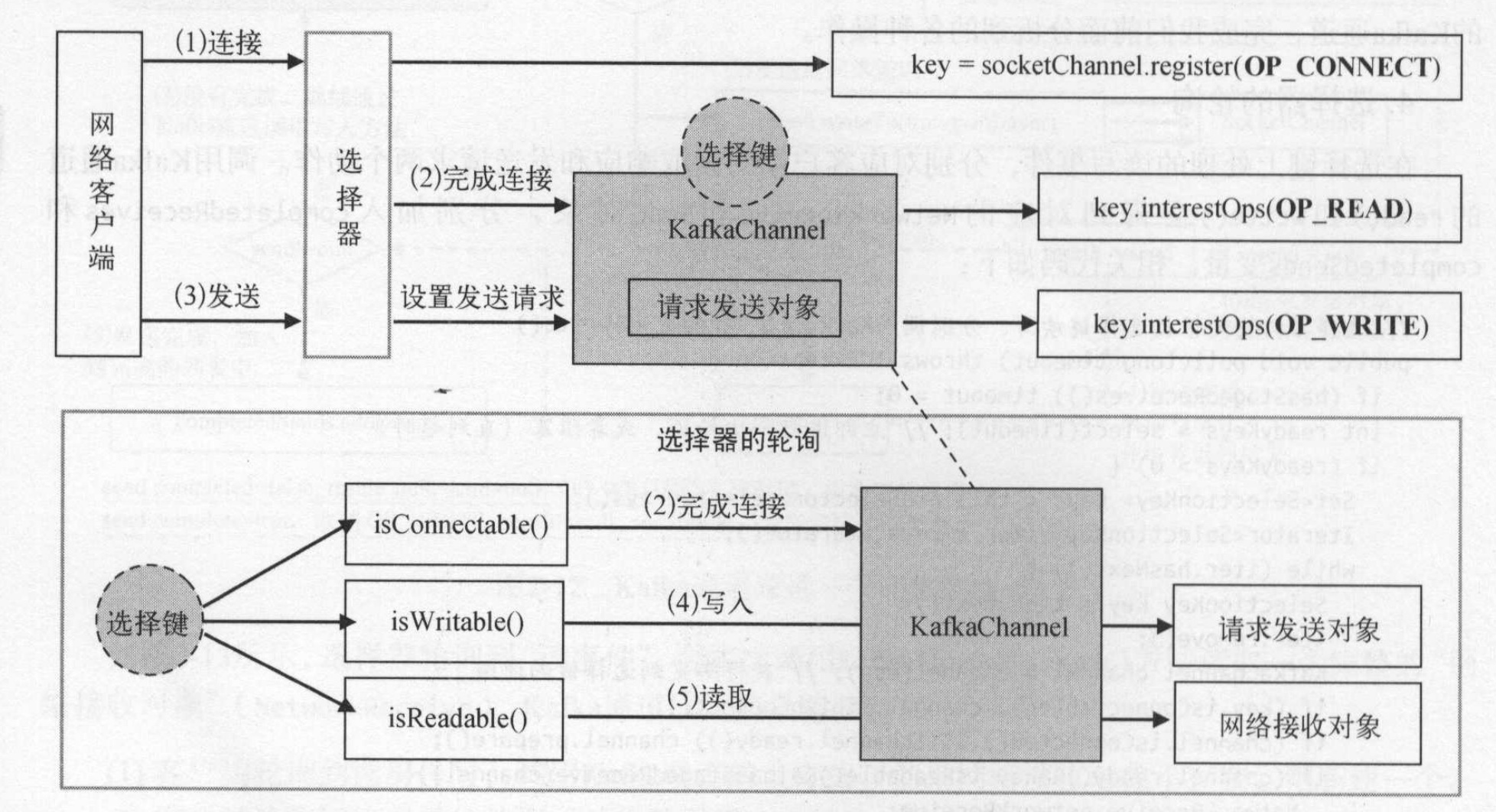
选择器会监听客户端的读写事件,选择器的乱想会根据选择键获取绑定在选择键上的Kafka通道。Kafka通道会将读写操作交给传输层,传输层再使用最底层的SocketChannel完成数据传输。 如图所示:
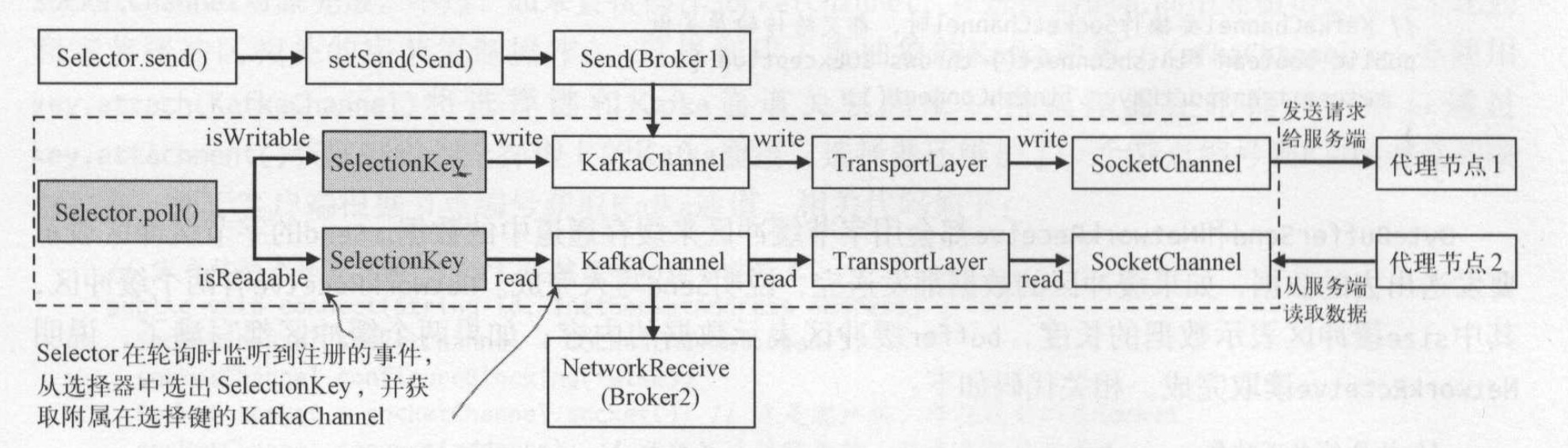
- 选择器轮询的时候,如果监听到写事件,则调用write()方法将客户端请求的Send对象发送到Kafka通道;如果发送完成则取消写监听完成,并将KafkaChannel中的send属性设置为null,可接受后续请求。如果没有完成,则继续监听写事件。
- 选择器轮询的时候,如果监听器监听到读事件,则调用read()方法从kafka通道读取代表服务端响应结果的NetworkReceive.
Kafka通道写入的具体过程:
- 发送请求时,通过kafka的setSend方法设置要发送的请求对象,并注册写事件。
- 客户端轮询到写事件时, 会取出kafka通道中的发送请求,并发送给网络通道。
- 如果本次写操作没有全部完成,那么由于写事件仍然存在,客户端会再次轮询写事件。
- 客户端新的轮询会继续发送请求,如果发送完成则取消写事件,并设置返回结果。
- 请求完成后,加入到completedSends集合中,这个数据会被调用者使用
- 请求已经全部发送完成,重置send对象为空,下一次请求才可以继续执行。
1 | /** |
Kafka通道读取的具体过程:
- 客户端轮询到读事件,调用KafkaChannel的读方法,如果网络接收对象不存在则创建一个。
- 客户端读取网络连接通道的数据,并将数据填充到网络连接对象
- 如果本次读操作没有全部完成,客户端还会继续轮询到读事件。
- 客户端新的轮询会继续读取网络通道中的数据,如果读取完成,则设置返回结果。
- 读取完成后,加入到暂时完成的列表中,这个数据会被调用者使用。
- 读取全部完成,重置网络接受对象为空,下一次新的读取请求才可以继续正常执行。
参考
- [1]《kafka权威指南》
- [2]《kafka技术内幕》
- [3] kafka源码